聚类
阈值法适用于灰度图像,因为可以很容易地根据直方图的众数来定义阈值。 然而,这种方法不能应用于彩色或多波段图像,因为它们没有直方图。 一个波段图像中的每个像素都可以表示为维空间中的一个点。 通过这种方式,颜色相近的像素会在该空间中形成群组,如Figure 1所示。

Figure 1:在维空间中显示彩色图像的像素。

颜色量化是指在尽可能保持图像颜色外观的同时,减少图像中不同颜色的数量。它有许多应用,如图像压缩(例如GIF)或基于内容的图像检索。
聚类方法可用于实现颜色量化,接下来我们来学习它的原理。
聚类方法旨在定义像素组。 因此,同一组中的所有像素在分割后的图像中定义一个类别。
一种经典的图像分割聚类方法是k-均值方法。
k-均值算法[Steinhaus 1957, MacQueen 1967] 是一种迭代方法,它将空间中的每个点分配到一个组(称为簇)中。 组数由用户选择。 在下文中,质心定义了一个组的中心。 其坐标是该组中各点坐标的平均值。
算法如下所示。
(随机)初始化个质心
当质心变化时:
步骤 A 对每个点:
计算点到所有质心的距离
将点分配到最近的组
步骤 B 计算每个组的质心
Figure 2图示了该算法, 在一个双波段图像(因此是二维空间)被分割成个类别的简单情况下。

Figure 2:k-均值算法图示。
Figure 3给出了在一幅图像上应用k-均值算法的结果。

Figure 3:在左图上使用k-均值算法进行分割(中:个类别,右:个类别)。
在一个三波段图像(因此是三维空间)被分割成个类别的情况下。
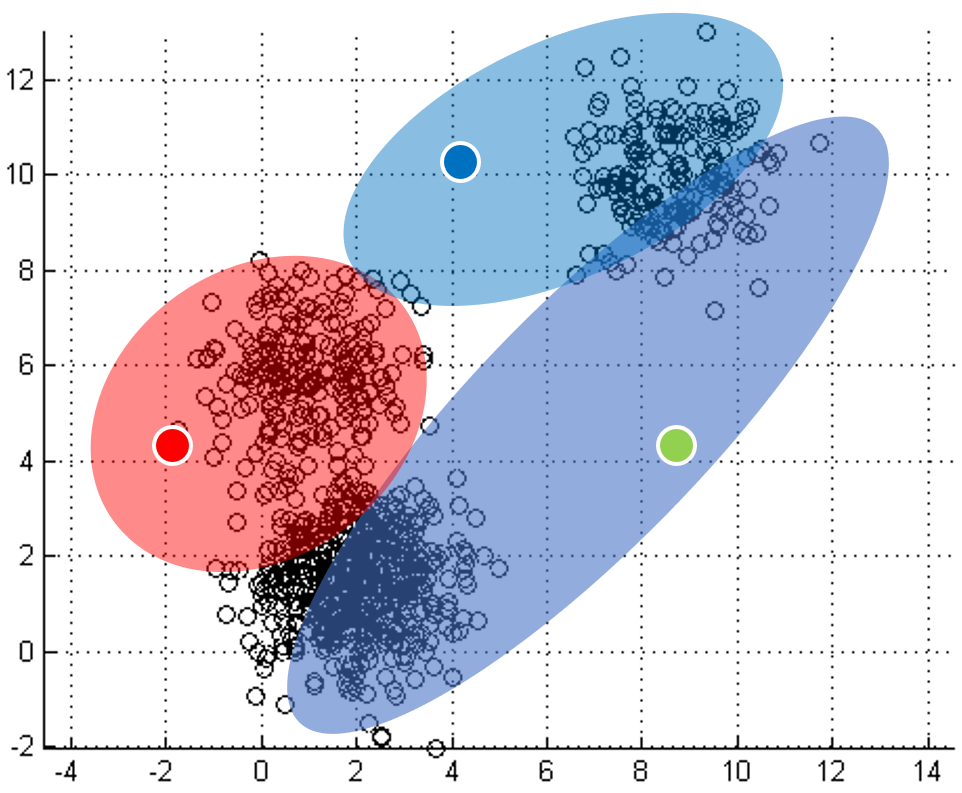
在二维空间(例如YCbCr颜色空间)中有3个簇的示例。每个点都被分配到其最近的质心
计算新簇的均值。
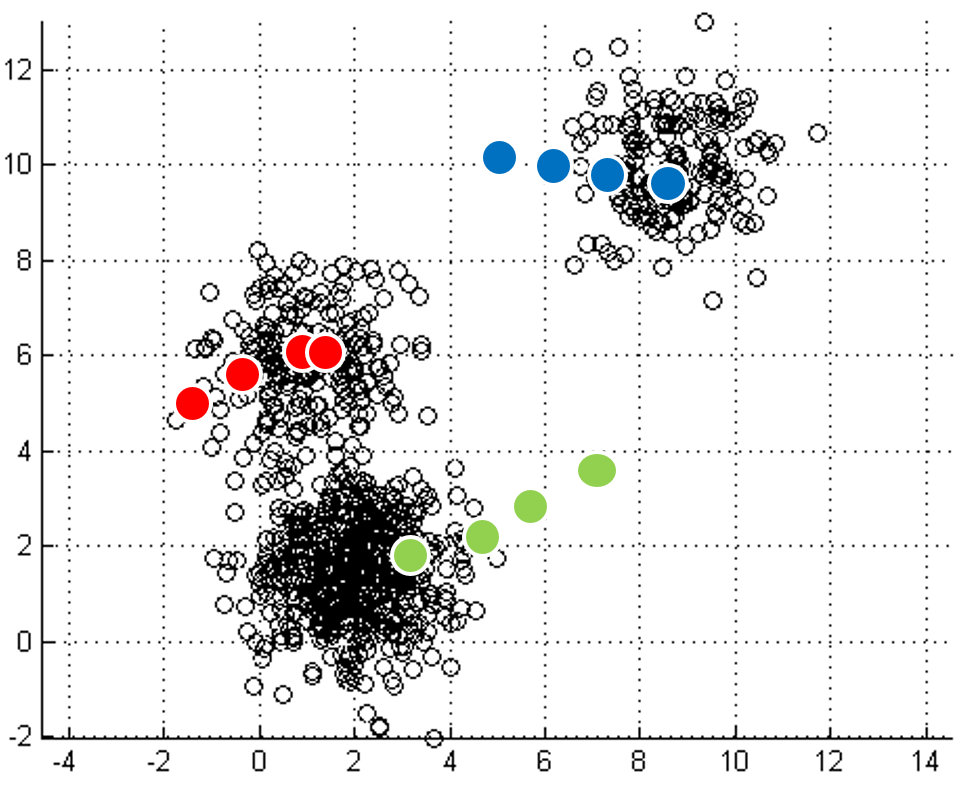
质心随时间演变的示例
重复上面两步骤直到收敛,即满足某个预先定义的标准。
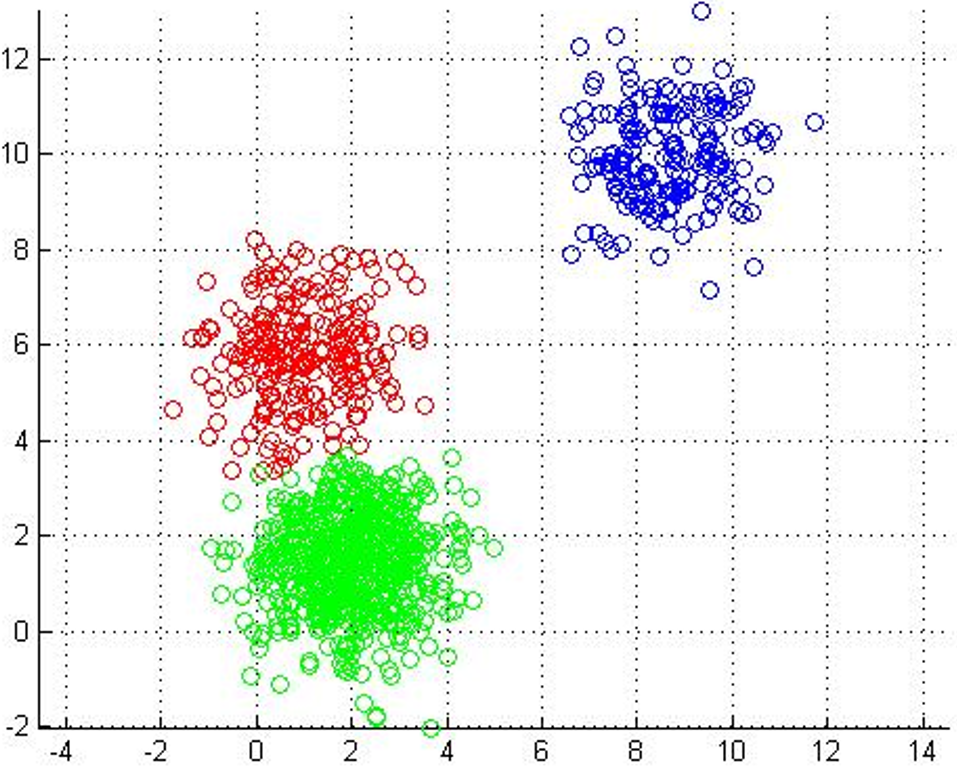
最终分割结果
无论工作空间的维度数量如何,该过程都是相同的。
k-均值方法用于图像分割的优缺点如下所列。
简单
易于实现
通常很快
当簇为球形时效果很好*
需要预先知道类别数
对初始化敏感
在高维空间中可能很慢
对非球形结构效果不佳*
对离群值敏感*
上面用*标识的特性现在详细说明。
因为k-均值算法是根据点到质心的距离进行分组的, 它假设组是球形的。 因此,该算法对球形簇效果很好,但如果簇不是球形的,则效果不佳, 如下图所示。

Figure 4:球形簇:k-均值算法效果很好。 点用表示,其颜色对应类别, 质心用黑色表示。

Figure 5:非球形簇:k-均值算法效果不佳。
此外,质心是作为簇中点的平均值来计算的。 但平均值不是一个稳健的估计,对远离群组的点很敏感。 因此,该算法在存在离群值(valeurs aberrantes)时可能会失败。

Figure 6:存在离群值:本例中k-均值算法效果不佳。
可以使用其他聚类方法来避免上述一些限制。 例如,我们可以引用高斯混合模型或均值漂移。
K-均值玩具示例(OpenCV)¶
我们可以使用OpenCV的实现[cv2.kmeans()]来观察在一个简单的一维案例(灰度图)中,迭代次数如何影响结果。下面的binarize_kmeans()函数使用个簇来对输入图像进行二值化。
import numpy as np
import cv2
import matplotlib.pyplot as plt
import matplotlib
import scipy.stats as stats
from ipywidgets import interact, fixed, widgets
# 本笔记本的默认图形尺寸
matplotlib.rcParams['figure.figsize'] = (10.0, 10.0)
# 复制到本书共享图像目录的图像路径
images_path = '../../../_images/segmentation/'
def binarize_kmeans(image, it):
"""使用k-均值(K=2)对图像进行二值化。
参数:
image:输入的二维数组(灰度图像)
it:最大迭代次数
"""
# 为质心设置随机种子以保证可复现性
cv2.setRNGSeed(124)
# 将图像展平为样本的列向量
flattened_img = image.reshape((-1, 1))
flattened_img = np.float32(flattened_img)
# Epsilon(移动阈值)
epsilon = 0.2
# 停止标准:达到`it`次迭代或质心移动小于epsilon
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, it, epsilon)
# K = 2 用于二值化
K = 2
# 使用随机初始中心运行k-均值
_, label, center = cv2.kmeans(flattened_img, K, None, criteria, it, cv2.KMEANS_RANDOM_CENTERS)
# 按中心值给标签着色
center = np.uint8(center)
flattened_img = center[label.flatten()]
# 重塑为原始形状
binarized = flattened_img.reshape(image.shape)
# 显示结果
plt.subplot(2, 1, 1)
plt.title("二值化图像")
plt.imshow(binarized, cmap='gray', vmin=0, vmax=255)
# 显示直方图如何被分割
plt.subplot(2, 1, 2)
plt.title("分割后的直方图")
plt.hist([image[binarized == center[0]].ravel(), image[binarized == center[1]].ravel()],
256, [0, 256], color=["black", "gray"], stacked=True)
关于停止标准的说明:我们可以在达到最大迭代次数时停止,或者当质心在一次迭代中的移动小于阈值(epsilon)时停止。
# 交互式演示(灰度板)
matplotlib.rcParams['figure.figsize'] = (10.0, 10.0)
image = cv2.imread(images_path + 'plate.jpg', 0)
interact(binarize_kmeans, image=fixed(image), it=(2, 5, 1))
K-均值:更深入的数学视角¶
K-均值可以理解为最小化簇内平方和(WCSS)目标函数:
该算法交替执行以下步骤:
分配步骤(给定质心 ):通过欧几里得距离将每个点分配给最近的质心。
更新步骤(给定分配):将 更新为簇 中点的均值。
这些是在非凸目标上的块坐标下降步骤,保证了 的单调非增和收敛到局部最优。欧几里得距离意味着特征空间中的球形Voronoi区域。这解释了:
对离群值的敏感性(均值不是稳健的估计量),
偏好大致球形的簇,以及
对初始化的敏感性(多个局部最小值)。
与概率模型的联系:如果每个簇都建模为具有共同方差和相等先验的各向同性高斯分布,则最大后验(MAP)分配简化为最近均值分类;在这种假设下,最小化平方距离与最大化(对数)似然相关。
期望最大化(EM)¶
**期望最大化(EM)**是K-均值算法的推广,其中每个簇由一个高斯分布表示,该分布由均值和协方差矩阵参数化,而不仅仅是一个质心。这是一种软聚类,因为它不给出像素属于或不属于某个簇的硬决策,而是给出该像素属于每个簇 的概率,即 。这意味着在算法的每次迭代中,不仅会优化每个簇的均值(如K-均值),还会优化它们的协方差矩阵。
下面我们在一个简单的二值化任务(灰度图)上演示EM,与K-均值的示例并行。
matplotlib.rcParams['figure.figsize'] = (10.0, 10.0)
cv2.setRNGSeed(5)
# 定义参数
n_clusters = 2
covariance_type = 0 # 0: 球形, 1: 对角, 2: 完整
n_iter = 10
epsilon = 0.2
# 创建EM对象并设置参数
em = cv2.ml.EM_create()
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, n_iter, epsilon)
em.setClustersNumber(n_clusters)
em.setCovarianceMatrixType(covariance_type)
em.setTermCriteria(criteria)
# 读取灰度图像
image = cv2.imread(images_path + 'plate.jpg', 0)
# 展平图像
flattened_img = image.reshape((-1, 1)).astype(np.float32)
# 训练EM
_, _, labels, _ = em.trainEM(flattened_img)
# 将标签重塑为图像大小(二值化)
binarized = labels.reshape(image.shape)
# 显示二值化图像
plt.subplot(2, 1, 1)
plt.title("二值化图像 (EM)")
plt.imshow(binarized, cmap="gray")
# --------------- 高斯可视化 ---------------
plt.subplot(2, 1, 2)
plt.title("簇似然 (一维高斯)")
means = em.getMeans(); covs = em.getCovs()
sigmas = np.sqrt(np.array(covs))[:, 0, 0]
means = np.array(means)[:, 0]
x = np.linspace(0, 256, 200)
for m, s in zip(means, sigmas):
plt.plot(x, stats.norm.pdf(x, loc=m, scale=s))
plt.legend([f'簇 {i+1}' for i in range(n_clusters)])
plt.show()
EM:更深入的数学视角¶
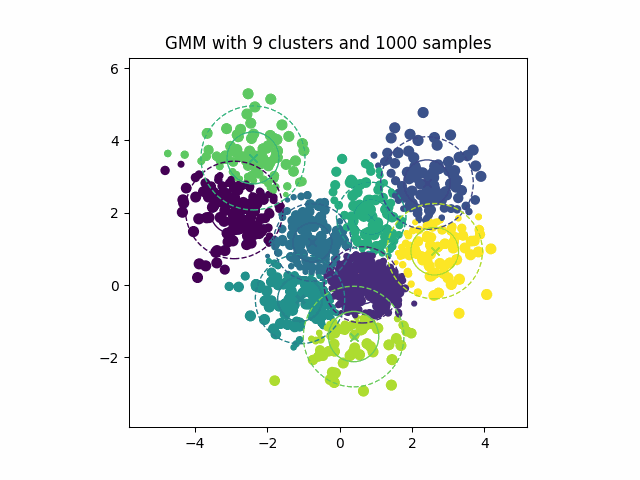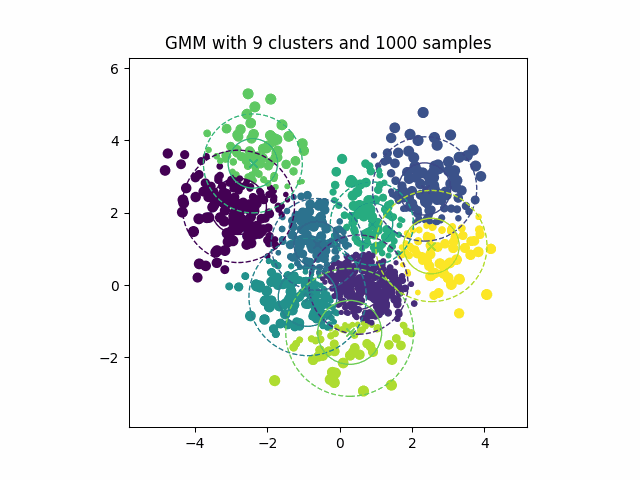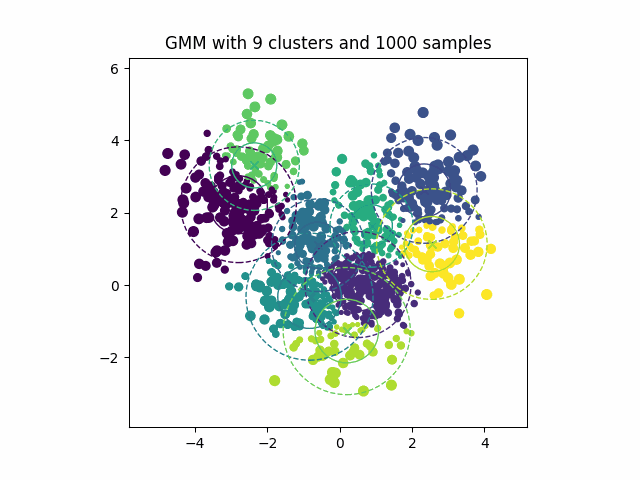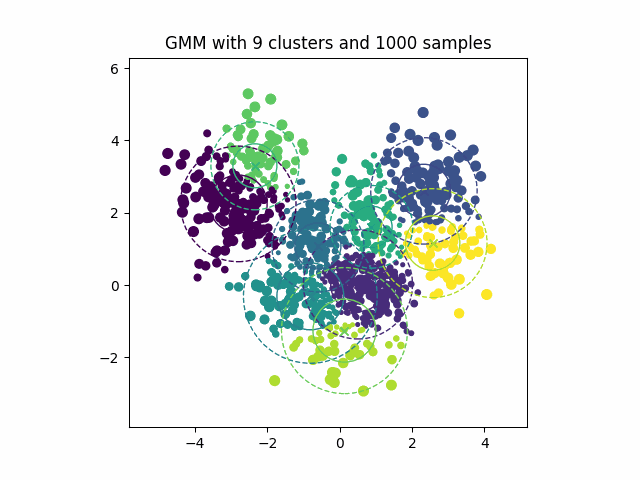
Figure 7:显示期望最大化算法迭代优化高斯混合分量以拟合数据分布的动画。
GMM完整数据对数似然的推导¶
在高斯混合模型(GMM)中,我们假设数据是由个高斯分布的混合生成的。我们引入一个潜在变量,它指示个高斯分量中的哪一个生成了每个数据点。
单个数据点的似然: 对于单个数据点 ,如果我们知道它是由第个高斯分量生成的(即 ),其概率为 。选择第个分量的先验概率是 。 和它来自第个分量的联合概率是 。
带有潜在变量的单个数据点的似然: 我们可以使用 指示变量(如果 来自第个分量,则为1,否则为0)更普遍地写出这一点。 属于任何分量 的概率可以写成所有分量的乘积:
由于对于某个 , 只有一个为1,因此该乘积简化为该 的联合概率。
完整数据似然: 假设所有数据点 都是独立同分布的(i.i.d.),完整数据(和)的总似然是各个似然的乘积:
完整数据对数似然: 对完整数据似然取对数,将乘积简化为和,这对于最大化来说更容易处理。
使用对数法则 ( 和 ):
高斯混合模型的EM算法¶
用于高斯混合模型(GMM)的EM算法旨在给定数据 的情况下,寻求参数 的最大似然估计。带有潜在分配 的完整数据对数似然为
EM算法在以下两个步骤之间交替进行:
E-步:计算责任(后验成员概率)
M-步:使用加权充分统计量更新参数
与K-均值的关系:
如果对所有 都有 (具有相等方差的球形)且 相等,那么随着 ,软分配会变得更清晰,EM算法简化为K-均值算法:硬性的最近均值分配,其中质心等于均值。
使用完整的 时,簇的形状是椭球体,距离实际上变成了马氏距离。
协方差结构:
球形: — 各向同性簇,每个簇有1个尺度参数。
对角: — 轴对齐的椭圆。
完整:无约束的 — 可捕捉不同波段间相关性的有向椭圆。
实践说明:OpenCV EM API¶
通过
em.setCovarianceMatrixType(...)设置协方差结构,其中0表示球形,1表示对角,2表示完整。在
em.trainEM(...)之后,可以使用em.getMeans()检索质心(均值);使用em.getCovs()检索协方差。