深度生成模型

生成模型简介¶

机器学习分类问题中的两大主要范式:
判别式模型:直接对给定输入数据 的标签 的条件概率 进行建模。
生成式模型:通过学习数据分布 和条件分布 来对联合概率 进行建模。
概率生成模型¶
概率生成模型是用于随机生成可观测数据的模型。
假设在连续或离散的高维空间 中,有一个服从未知数据分布 的随机向量 ,其中 。生成模型基于一些可观测样本 来学习一个参数模型 以近似未知分布 。然后可以使用该模型生成与“真实”样本相似的新样本。

生成模型的关键功能¶
生成模型有两个基本功能:
概率密度估计:基于数据集估计概率密度函数 。
采样:生成服从该分布的新样本。

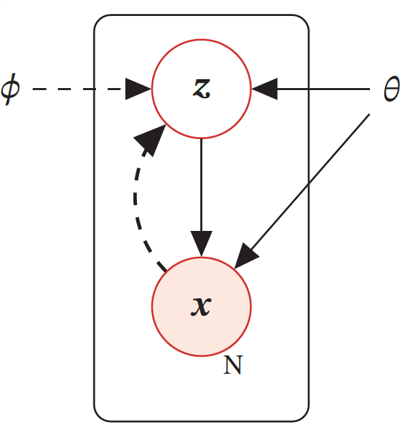
柏拉图的洞穴寓言与隐变量¶
隐变量的概念可以通过柏拉图的洞穴寓言等类比来理解,我们观察到的只是真实形式(隐变量)的影子(可观测数据)。

现实世界是复杂的,我们往往无法直接测量我们感兴趣的事物。相反,我们收集可观测数据。例如,可以测量的脑电波数据 实际上是由大脑的某些潜在(隐藏)变量 决定的。

自编码器¶
自编码器的基本架构¶
自编码器通过编码输入 获得低维向量 ,然后基于该向量将输入重构为 。通过最小化 和 之间的重构误差(例如,损失函数 ),训练神经网络以实现无监督学习。

隐空间维度¶
隐空间的维度影响重构数据的质量。自编码器可以看作是一种压缩形式,其中较小的隐空间对应较高的压缩率。

自编码器的局限性¶
自编码器通过最小化重构误差来学习隐式表示,使得低维隐空间能够捕获原始数据的信息。
然而,自编码器的泛化能力有限。它只能生成对应于原始数据的隐变量,而无法泛化以生成新内容。变分自编码器(VAE)被提出来解决这个问题。
变分自编码器 (VAE)¶
从自编码器到VAE¶
VAE 扩展了自编码器,以学习从输入到隐空间的概率映射。

VAE 解码器¶
变分自编码器的主要特点是它们可以在一定程度上解释(实际上是生成)未知的编码(隐向量),即不是从原始数据生成的编码。

概率隐空间¶
与仅生成单个编码的自编码器不同,变分自编码器强调生成编码的概率分布。然后解码器从概率分布中抽取一个编码样本来重构原始数据。

VAE中的高斯假设¶
VAE 假设隐变量服从高斯分布。生成高斯密度函数只需要确定均值 和协方差矩阵 。
如果数据量不大,隐空间的概率分布可能会形成一个非常窄的高斯分布,将大部分质量集中在均值 附近。

VAE 目标¶
关键思想是使用神经网络来拟合两个复杂的条件概率分布:编码器 和解码器 。
除了重构误差外,还在损失函数中添加了一个正则化项,以确保隐空间分布不会变得太窄:。

VAE 的数学公式¶
该生成模型的联合概率密度函数可以分解为:
其中 是隐变量 的先验分布的概率密度函数,而 是当 已知时观测变量 的条件概率密度函数。 表示这两个密度函数的参数。一般来说,我们可以假设 和 是某种参数化的分布族,例如正态分布。这些分布的形式是已知的,但参数 是未知的,可以通过最大化似然来估计。
令
称为证据下界 (Evidence Lower Bound, ELBO)。
ELBO 与对数边际似然之间的确切关系是:
由于 KL 散度是非负的,我们得到证据下界 (ELBO) 不等式:
变分推断¶
传统的微积分通常用于寻找函数 的极值点,而变分法用于寻找一个函数 ,使泛函 (函数的函数)获得最大值或最小值。通常我们要计算后验概率:
但对于许多模型,计算 的积分通常是不可行的(积分没有闭式解,或者计算复杂度是指数级的)。
一种解决方案是使用变分法找到一个更简单的分布 来近似后验概率 ,这称为变分推断。这样,推断问题就转化为泛函优化问题:
其中 是候选概率分布族。 与变分推断的思想一致,在变分自编码器中,由于 难以直接计算,我们无法直接最小化 KL 散度。相反,我们最大化 :
那么:
即,推断网络的目标转化为寻找一组网络参数 以最大化证据下界 。
推断网络和生成网络¶
推断网络的目标是使变分分布 尽可能接近真实的后验分布 ,即最小化两个分布之间的 KL 散度:
给定隐变量 ,生成网络的目标是最大化原始数据出现的可能性,即最大化似然函数:
ELBO 分解的推导:我们可以将联合概率 拆分为 :
现在,回想一下 KL 散度 的定义:
正则化项正是 ,即 负的 KL 散度。将其代回得到最终的 ELBO 方程:
VAE 损失函数¶
最大化证据下界 可以完成整个网络的目标。但通常我们需要将其转换为最小化损失函数:
第一项是负似然期望作为重构误差,第二项是正则化项,以确保变分分布不会太窄而失去泛化能力。
高斯分布的 KL 散度¶
为简单起见,我们假设 和 。
这两个高斯分布之间的 KL 散度有一个闭式解:
实际 VAE 损失¶
在实践中,重构项通常实现为 MSE 或 BCE,具体取决于假设的似然模型:
MSE 对应于 的(对角)高斯似然。
BCE 对应于伯努利似然(常见于 MNIST,当像素缩放到 时;这也是示例代码所使用的)。
具有正则化权重 和各向同性标准高斯先验 ,损失变为:
展开 KL 散度项:
正则化隐空间¶
最小化正则化项强制隐空间分布接近标准高斯分布,从而确保连续性和完整性。
正则化保证了隐空间的两个重要属性:
连续性:隐空间中两个接近的点在解码后不应给出完全不同的内容
完整性:对于选定的分布,从隐空间采样的点在解码后应给出“有意义的”内容。



重参数化技巧¶
为了允许反向传播通过采样过程,我们使用重参数化技巧。对于 ,我们可以写成 ,其中 。


-VAE¶
当 KL 散度项的权重 时,模型 (-VAE) 可以学习到更多解耦的特征。


import os
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
from torchvision import transforms
from torchvision.utils import save_image
import matplotlib.pyplot as plt
import numpy as np
# 配置中文字体支持
plt.rcParams['font.sans-serif'] = [
'Noto Sans CJK SC', 'Noto Sans CJK JP', 'SimHei',
'Microsoft YaHei', 'WenQuanYi Micro Hei', 'DejaVu Sans'
]
plt.rcParams['axes.unicode_minus'] = False
# 设备配置
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 如果不存在则创建目录
sample_dir = '../../../data/vae_samples'
if not os.path.exists(sample_dir):
os.makedirs(sample_dir)
# 超参数
image_size = 784
h_dim = 400
z_dim = 20
num_epochs = 15
batch_size = 128
learning_rate = 1e-3
# MNIST 数据集
dataset = torchvision.datasets.MNIST(root='../../../dataset/mnist',
train=True,
transform=transforms.ToTensor(),
download=True)
# 数据加载器
data_loader = torch.utils.data.DataLoader(dataset=dataset,
batch_size=batch_size,
shuffle=True)
# VAE 模型
class VAE(nn.Module):
def __init__(self, image_size=784, h_dim=400, z_dim=20):
super(VAE, self).__init__()
self.fc1 = nn.Linear(image_size, h_dim)
self.fc2 = nn.Linear(h_dim, z_dim)
self.fc3 = nn.Linear(h_dim, z_dim)
self.fc4 = nn.Linear(z_dim, h_dim)
self.fc5 = nn.Linear(h_dim, image_size)
def encode(self, x):
h = F.relu(self.fc1(x))
return self.fc2(h), self.fc3(h)
def reparameterize(self, mu, log_var):
std = torch.exp(0.5*log_var)
eps = torch.randn_like(std)
return mu + eps*std
def decode(self, z):
h = F.relu(self.fc4(z))
return torch.sigmoid(self.fc5(h))
def forward(self, x):
mu, log_var = self.encode(x.view(-1, image_size))
z = self.reparameterize(mu, log_var)
x_reconst = self.decode(z)
return x_reconst, mu, log_var
model = VAE().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# 损失函数
def loss_function(recon_x, x, mu, log_var):
BCE = F.binary_cross_entropy(recon_x, x.view(-1, 784), reduction='sum')
KLD = -0.5 * torch.sum(1 + log_var - mu.pow(2) - log_var.exp())
return BCE + KLD
# 开始训练
for epoch in range(num_epochs):
for i, (x, _) in enumerate(data_loader):
x = x.to(device)
x_reconst, mu, log_var = model(x)
loss = loss_function(x_reconst, x, mu, log_var)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 100 == 0:
print ("Epoch[{}/{}], Step [{}/{}], Reconst Loss: {:.4f}"
.format(epoch+1, num_epochs, i+1, len(data_loader), loss.item()/len(x)))
# 保存并显示图像
with torch.no_grad():
# 保存采样图像
z = torch.randn(batch_size, z_dim).to(device)
out = model.decode(z).view(-1, 1, 28, 28)
save_image(out, os.path.join(sample_dir, f'sampled-{epoch+1}.png'))
# 保存重构图像
out, _, _ = model(x)
x_concat = torch.cat([x.view(-1, 1, 28, 28), out.view(-1, 1, 28, 28)], dim=3)
save_image(x_concat, os.path.join(sample_dir, f'reconst-{epoch+1}.png'))
# 可视化重构图像
fig = plt.figure(figsize=(10, 2))
plt.suptitle("重构图像 (奇数: 原始, 偶数: 重构)")
for i in range(10):
ax = fig.add_subplot(2, 10, i + 1)
ax.imshow(x[i].cpu().numpy().reshape(28, 28), cmap='gray')
ax.axis('off')
ax = fig.add_subplot(2, 10, i + 11)
ax.imshow(out[i].cpu().numpy().reshape(28, 28), cmap='gray')
ax.axis('off')
plt.show()
# 可视化生成图像
fig = plt.figure(figsize=(10, 2))
plt.suptitle("生成图像")
z = torch.randn(20, z_dim).to(device)
generated = model.decode(z)
for i in range(20):
ax = fig.add_subplot(2, 10, i + 1)
ax.imshow(generated[i].cpu().numpy().reshape(28, 28), cmap='gray')
ax.axis('off')
plt.show()Epoch[1/15], Step [100/469], Reconst Loss: 184.0882
Epoch[1/15], Step [200/469], Reconst Loss: 152.5392
Epoch[1/15], Step [300/469], Reconst Loss: 137.1306
Epoch[1/15], Step [400/469], Reconst Loss: 133.7657
Epoch[2/15], Step [100/469], Reconst Loss: 127.7568
Epoch[2/15], Step [200/469], Reconst Loss: 119.4925
Epoch[2/15], Step [300/469], Reconst Loss: 126.1581
Epoch[2/15], Step [400/469], Reconst Loss: 121.0710
Epoch[3/15], Step [100/469], Reconst Loss: 109.6203
Epoch[3/15], Step [200/469], Reconst Loss: 114.4937
Epoch[3/15], Step [300/469], Reconst Loss: 110.6404
Epoch[3/15], Step [400/469], Reconst Loss: 112.5234
Epoch[4/15], Step [100/469], Reconst Loss: 111.6060
Epoch[4/15], Step [200/469], Reconst Loss: 107.1323
Epoch[4/15], Step [300/469], Reconst Loss: 110.7865
Epoch[4/15], Step [400/469], Reconst Loss: 109.6746
Epoch[5/15], Step [100/469], Reconst Loss: 113.1342
Epoch[5/15], Step [200/469], Reconst Loss: 109.6219
Epoch[5/15], Step [300/469], Reconst Loss: 109.4858
Epoch[5/15], Step [400/469], Reconst Loss: 107.1039
Epoch[6/15], Step [100/469], Reconst Loss: 110.7190
Epoch[6/15], Step [200/469], Reconst Loss: 110.0675
Epoch[6/15], Step [300/469], Reconst Loss: 107.8059
Epoch[6/15], Step [400/469], Reconst Loss: 109.4669
Epoch[7/15], Step [100/469], Reconst Loss: 104.5772
Epoch[7/15], Step [200/469], Reconst Loss: 110.3899
Epoch[7/15], Step [300/469], Reconst Loss: 109.6058
Epoch[7/15], Step [400/469], Reconst Loss: 106.6430
Epoch[8/15], Step [100/469], Reconst Loss: 109.8076
Epoch[8/15], Step [200/469], Reconst Loss: 103.2654
Epoch[8/15], Step [300/469], Reconst Loss: 105.7348
Epoch[8/15], Step [400/469], Reconst Loss: 106.3147
Epoch[9/15], Step [100/469], Reconst Loss: 105.2917
Epoch[9/15], Step [200/469], Reconst Loss: 108.1727
Epoch[9/15], Step [300/469], Reconst Loss: 105.5469
Epoch[9/15], Step [400/469], Reconst Loss: 104.8924
Epoch[10/15], Step [100/469], Reconst Loss: 108.8192
Epoch[10/15], Step [200/469], Reconst Loss: 107.1760
Epoch[10/15], Step [300/469], Reconst Loss: 108.2187
Epoch[10/15], Step [400/469], Reconst Loss: 107.9864
Epoch[11/15], Step [100/469], Reconst Loss: 106.9739
Epoch[11/15], Step [200/469], Reconst Loss: 104.3344
Epoch[11/15], Step [300/469], Reconst Loss: 106.2429
Epoch[11/15], Step [400/469], Reconst Loss: 108.8376
Epoch[12/15], Step [100/469], Reconst Loss: 105.5174
Epoch[12/15], Step [200/469], Reconst Loss: 107.1364
Epoch[12/15], Step [300/469], Reconst Loss: 101.9232
Epoch[12/15], Step [400/469], Reconst Loss: 102.3678
Epoch[13/15], Step [100/469], Reconst Loss: 102.1006
Epoch[13/15], Step [200/469], Reconst Loss: 107.0383
Epoch[13/15], Step [300/469], Reconst Loss: 109.7840
Epoch[13/15], Step [400/469], Reconst Loss: 104.2295
Epoch[14/15], Step [100/469], Reconst Loss: 106.8961
Epoch[14/15], Step [200/469], Reconst Loss: 105.8796
Epoch[14/15], Step [300/469], Reconst Loss: 103.7608
Epoch[14/15], Step [400/469], Reconst Loss: 102.5690
Epoch[15/15], Step [100/469], Reconst Loss: 103.5242
Epoch[15/15], Step [200/469], Reconst Loss: 103.3903
Epoch[15/15], Step [300/469], Reconst Loss: 103.4699
Epoch[15/15], Step [400/469], Reconst Loss: 100.8792


生成对抗网络 (GAN)¶
GAN 简介¶
变分自编码器、深度信念网络等都是从预先构建的样本中得到的概率密度模型(例如,变分自编码器假设高斯分布),并通过最大似然估计求解模型参数(例如,均值和协方差矩阵),称为显式密度模型。
实际上,许多复杂的概率密度模型无法简单建模,因此我们直接从数据中拟合一个生成器 。虽然生成器的内部结构通常以黑盒形式存在,但在一定程度上,任何随机输入都可以生成符合原始数据分布的结果。这种模型称为隐式密度模型。
生成对抗网络是一种隐式密度模型。它利用神经网络强大的拟合能力来学习一个符合原始数据分布的生成网络。
生成对抗网络既不依赖标签进行优化,也不根据结果的奖惩调整参数。它是基于生成器网络和判别器网络之间的对抗博弈不断优化的。
类似于验钞机和造假币机器之间的对抗博弈,两者不断博弈,博弈的结果是假币越来越像真币,直到验钞机无法区分货币是假币还是真币。

对抗过程¶
生成对抗网络允许生成器和判别器相互对抗:一方面,生成器尽最大努力将噪声转化为逼真的合成数据,另一方面,判别器尽最大努力区分合成数据和真实数据。进行交替训练,最终收敛到无法判断样本真伪的地步。
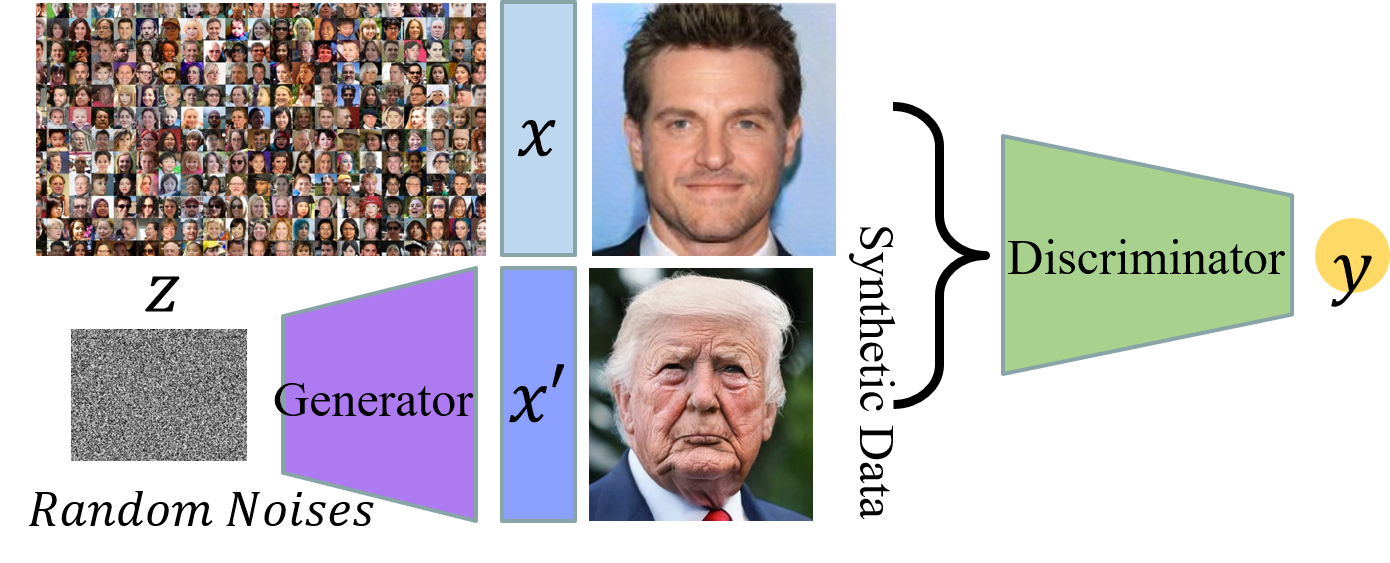
Figure 24:GAN 训练动画展示了生成器和判别器之间的对抗过程。
GAN 目标函数¶
判别器目标:
生成器目标:
是 为真实数据的概率。
实现说明:上述生成器目标是原始的极小极大公式。在实践中,当判别器过强时(即 ),此目标可能会出现梯度消失问题。示例代码使用非饱和损失:,它能提供更好的梯度信号和更稳定的训练。
生成器作为分布变换器¶
生成器学习将随机噪声变换为数据分布上的点。


import os
import torch
import torch.nn as nn
import torchvision
from torchvision import transforms
from torchvision.utils import save_image
import matplotlib.pyplot as plt
import numpy as np
# 配置中文字体支持
plt.rcParams['font.sans-serif'] = [
'Noto Sans CJK SC', 'Noto Sans CJK JP', 'SimHei',
'Microsoft YaHei', 'WenQuanYi Micro Hei', 'DejaVu Sans'
]
plt.rcParams['axes.unicode_minus'] = False
# 设备配置
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 如果不存在则创建目录
sample_dir = '../../../data/gan_samples'
if not os.path.exists(sample_dir):
os.makedirs(sample_dir)
# 超参数
latent_size = 64
hidden_size = 256
image_size = 784
num_epochs = 200
batch_size = 100
learning_rate = 0.0002
# 图像处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(0.5,),
std=(0.5,))])
# MNIST 数据集
mnist = torchvision.datasets.MNIST(root='../../../dataset/mnist',
train=True,
transform=transform,
download=True)
# 数据加载器
data_loader = torch.utils.data.DataLoader(dataset=mnist,
batch_size=batch_size,
shuffle=True)
# 判别器
D = nn.Sequential(
nn.Linear(image_size, hidden_size),
nn.LeakyReLU(0.2),
nn.Linear(hidden_size, hidden_size),
nn.LeakyReLU(0.2),
nn.Linear(hidden_size, 1),
nn.Sigmoid())
# 生成器
G = nn.Sequential(
nn.Linear(latent_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, image_size),
nn.Tanh())
# 设备设置
D = D.to(device)
G = G.to(device)
# 二元交叉熵损失和优化器
criterion = nn.BCELoss()
d_optimizer = torch.optim.Adam(D.parameters(), lr=learning_rate)
g_optimizer = torch.optim.Adam(G.parameters(), lr=learning_rate)
def denorm(x):
out = (x + 1) / 2
return out.clamp(0, 1)
def reset_grad():
d_optimizer.zero_grad()
g_optimizer.zero_grad()
# 开始训练
total_step = len(data_loader)
for epoch in range(num_epochs):
for i, (images, _) in enumerate(data_loader):
images = images.reshape(batch_size, -1).to(device)
# 定义图像是真实还是虚假的标签
real_labels = torch.ones(batch_size, 1).to(device)
fake_labels = torch.zeros(batch_size, 1).to(device)
# ================================================================== #
# 训练判别器 #
# ================================================================== #
# 使用真实图像计算 BCE 损失
outputs = D(images)
d_loss_real = criterion(outputs, real_labels)
real_score = outputs
# 使用生成图像(由潜在空间点生成)计算 BCE 损失
z = torch.randn(batch_size, latent_size).to(device)
fake_images = G(z)
outputs = D(fake_images)
d_loss_fake = criterion(outputs, fake_labels)
fake_score = outputs
# 判别器总损失
d_loss = d_loss_real + d_loss_fake
# 清除梯度并反向传播
reset_grad()
d_loss.backward()
d_optimizer.step()
# ================================================================== #
# 训练生成器 #
# ================================================================== #
# 非饱和生成器损失:我们希望生成器欺骗判别器,
# 因此使用 real_labels 作为目标。当 D(G(z)) 接近 0 时,
# 这比极小极大目标提供更好的梯度。
z = torch.randn(batch_size, latent_size).to(device)
fake_images = G(z)
outputs = D(fake_images)
g_loss = criterion(outputs, real_labels)
# 清除梯度并反向传播
reset_grad()
g_loss.backward()
g_optimizer.step()
if (i+1) % 200 == 0:
print('Epoch [{}/{}], Step [{}/{}], d_loss: {:.4f}, g_loss: {:.4f}, D(x): {:.2f}, D(G(z)): {:.2f}'
.format(epoch, num_epochs, i+1, total_step, d_loss.item(), g_loss.item(),
real_score.mean().item(), fake_score.mean().item()))
# 保存真实图像
if (epoch+1) == 1:
images = images.reshape(images.size(0), 1, 28, 28)
save_image(denorm(images), os.path.join(sample_dir, 'real_images.png'))
# 保存采样图像
fake_images = fake_images.reshape(fake_images.size(0), 1, 28, 28)
save_image(denorm(fake_images), os.path.join(sample_dir, 'fake_images-{}.png'.format(epoch+1)))
# 保存模型检查点
torch.save(G.state_dict(), os.path.join(sample_dir, 'G.ckpt'))
torch.save(D.state_dict(), os.path.join(sample_dir, 'D.ckpt'))
# 可视化
real_images_path = os.path.join(sample_dir, 'real_images.png')
fake_images_path = os.path.join(sample_dir, f'fake_images-{num_epochs}.png')
fig = plt.figure(figsize=(10, 5))
plt.subplot(1,2,1)
plt.title("真实图像");
plt.axis('off')
plt.imshow(np.transpose(torchvision.io.read_image(real_images_path),(1,2,0)))
plt.subplot(1,2,2)
plt.title("伪造图像")
plt.axis('off')
plt.imshow(np.transpose(torchvision.io.read_image(fake_images_path),(1,2,0)))
plt.show()
VAE 与 GAN¶
生成图像的比较¶
视觉质量:与 VAE 相比,GAN 通常生成更清晰、高保真的图像。VAE 经常产生模糊的输出,因为它们优化的是重构损失(如 MSE 或 BCE),这往往会平均化细节和锐利的边缘。通过对抗损失优化的 GAN 被迫产生与真实数据无法区分的输出,从而保留了高频细节。

主要区别¶
目标与方法:两者都是用于采样、修复和密度估计的生成模型。VAE 使用显式密度模型最大化似然下界 (ELBO)。GAN 通过生成器和判别器之间的博弈隐式定义模型。
隐空间结构:
VAE:通过 KL 散度项强制执行正则化的隐空间(通常是高斯分布)。这导致了平滑、连续的隐空间,其中插值会产生有意义的语义转换(例如,逐渐改变角度、形状或表情)。这使得 VAE 非常适合表示学习。
GAN:在标准公式中没有明确正则化隐空间。虽然通常是连续的,但它可能不像 VAE 那样结构化,并且将数据映射回隐空间(推断)不是固有的(需要额外的机制)。
训练稳定性:
VAE:训练通常是稳定的,并且遵循定义良好的目标函数的标准优化。
GAN:训练是一个极小极大博弈,可能不稳定。常见问题包括:
模式崩溃 (Mode Collapse):生成器产生有限种类的样本(用少数“安全”示例欺骗判别器),而不是覆盖整个数据分布。
梯度消失:如果判别器太好,生成器可能收不到有用的梯度信号(在原始公式中)。
不收敛:模型参数可能会振荡而不是收敛。
稳定性方面的进展¶
为了解决 GAN 训练的不稳定性,提出了替代的距离度量,如 Wasserstein 距离 (WGAN)。即使生成器远离数据分布,WGAN 也能提供更平滑的梯度信号,从而显著提高稳定性。
VAE 与 GAN 总结表¶
| 特征 | 变分自编码器 (VAE) | 生成对抗网络 (GAN) |
|---|---|---|
| 输出质量 | 通常模糊 | 清晰,逼真的细节 |
| 训练 | 稳定,易于训练 | 不稳定(模式崩溃,振荡) |
| 隐空间 | 平滑,连续,可解释 | 结构较少,无固有推断 |
| 目标 | 最大化 ELBO (似然下界) | 极小极大博弈 (对抗损失) |
总结¶
本章探讨了 深度生成模型 的迷人世界,重点关注两个强大的框架:
变分自编码器 (VAEs):
建立在概率图模型和变分推断之上。
结合了 推断网络 (编码器) 将数据映射到隐分布 和 生成网络 (解码器) 重构数据 。
优化 证据下界 (ELBO),平衡重构质量与结构化隐空间的正则化项 (KL 散度)。
产生平滑、连续的隐式表示,非常适合插值和属性操作。
生成对抗网络 (GANs):
基于博弈论,涉及两个网络之间的极小极大博弈:
生成器 () 试图从噪声中创建逼真的数据来欺骗判别器。
判别器 () 试图区分真实数据和 生成的伪造数据。
能够生成极其清晰和高保真的图像。
以训练挑战如不稳定性和模式崩溃而闻名,这导致了像 Wasserstein GANs (WGAN) 这样的改进。
通过理解 VAE(训练稳定,隐空间结构化,输出稍模糊)和 GAN(输出更清晰,训练不稳定,隐空间可解释性较差)之间的权衡,我们可以为各种生成任务选择合适的工具。