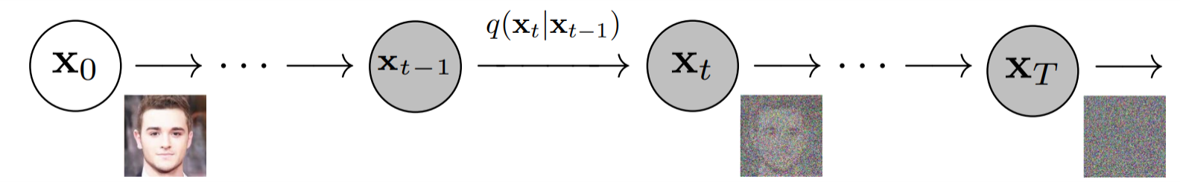去噪扩散概率模型
扩散模型改进
隐扩散模型
扩散模型实例
典型扩散模型
去噪扩散概率模型概述 ¶ 生成模型前景
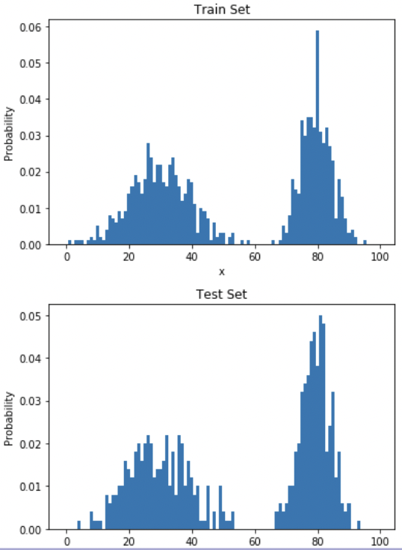
样本密度分布建模 ¶ 假设所有样本都来自分布 p d a t a ( x ) p_{data}(x) p d a t a ( x )
现有生成模型方法:VAE与GAN ¶ VAE:
L V A E ( θ , ϕ ) = − log p θ ( x ) + D K L ( q ϕ ( z ∣ x ) ∥ p θ ( z ∣ x ) ) = − E z ∼ q ϕ ( z ∣ x ) log p θ ( x ∣ z ) + D K L ( q ϕ ( z ∣ x ) ∥ p θ ( z ) ) θ ∗ , ϕ ∗ = arg min θ , ϕ L V A E − L V A E = log p θ ( x ) − D K L ( q ϕ ( z ∣ x ) ∥ p θ ( z ∣ x ) ) ≤ log p θ ( x ) \begin{aligned}
L_{\mathrm{VAE}}(\theta, \phi) & =-\log p_\theta(\mathbf{x})+D_{\mathrm{KL}}\left(q_\phi(\mathbf{z} \mid \mathbf{x}) \| p_\theta(\mathbf{z} \mid \mathbf{x})\right) \\
& =-\mathbb{E}_{\mathbf{z} \sim q_\phi(\mathbf{z} \mid \mathbf{x})} \log p_\theta(\mathbf{x} \mid \mathbf{z})+D_{\mathrm{KL}}\left(q_\phi(\mathbf{z} \mid \mathbf{x}) \| p_\theta(\mathbf{z})\right) \\
\theta^*, \phi^* & =\arg \min _{\theta, \phi} L_{\mathrm{VAE}} \\
-L_{\mathrm{VAE}} & =\log p_\theta(\mathbf{x})-D_{\mathrm{KL}}\left(q_\phi(\mathbf{z} \mid \mathbf{x}) \| p_\theta(\mathbf{z} \mid \mathbf{x})\right) \leq \log p_\theta(\mathbf{x})
\end{aligned} L VAE ( θ , ϕ ) θ ∗ , ϕ ∗ − L VAE = − log p θ ( x ) + D KL ( q ϕ ( z ∣ x ) ∥ p θ ( z ∣ x ) ) = − E z ∼ q ϕ ( z ∣ x ) log p θ ( x ∣ z ) + D KL ( q ϕ ( z ∣ x ) ∥ p θ ( z ) ) = arg θ , ϕ min L VAE = log p θ ( x ) − D KL ( q ϕ ( z ∣ x ) ∥ p θ ( z ∣ x ) ) ≤ log p θ ( x ) GAN:
min G max D L ( D , G ) = E x ∼ p r ( x ) [ log D ( x ) ] + E z ∼ p z ( z ) [ log ( 1 − D ( G ( z ) ) ) ] = E x ∼ p r ( x ) [ log D ( x ) ] + E x ∼ p g ( x ) [ log ( 1 − D ( x ) ) ] \begin{aligned}
\min _G \max _D L(D, G) & =\mathbb{E}_{x \sim p_r(x)}[\log D(x)]+\mathbb{E}_{z \sim p_z(z)}[\log (1-D(G(z)))] \\
& =\mathbb{E}_{x \sim p_r(x)}[\log D(x)]+\mathbb{E}_{x \sim p_g(x)}[\log (1-D(x))]
\end{aligned} G min D max L ( D , G ) = E x ∼ p r ( x ) [ log D ( x )] + E z ∼ p z ( z ) [ log ( 1 − D ( G ( z )))] = E x ∼ p r ( x ) [ log D ( x )] + E x ∼ p g ( x ) [ log ( 1 − D ( x ))] 数学上可以证明,训练 GAN 等价于最小化真实数据和生成数据之间的 Jensen-Shannon 散度。当生成器完美时(p g = p r p_g = p_r p g = p r − 2 log 2 -2\log2 − 2 log 2
L ( G , D ∗ ) = 2 D J S ( p r ∣ ∣ p g ) − 2 log 2 L(G,D^*) = 2D_{JS}(p_r||p_g)- 2\log{2} L ( G , D ∗ ) = 2 D J S ( p r ∣∣ p g ) − 2 log 2 生成模型的挑战与对比 ¶ 扩散模型的物理原理与设计思想 ¶ 扩散作用是一个基于分子热运动的运输现象,是分子通过布朗运动从高浓度区域 (或 高化势) 向低浓度区域 (或低化势) 的运输的过程。它是趋向于热平衡态的弛豫过程。 菲克定律 (Fick’s laws) 是扩散作用的近似描述,实际过程是从高化势区域向低化势区域的转移。扩散作用的速率和混合物的浓度梯度一般不太大,因此通常可以用近平衡态热力学理论进行处理。
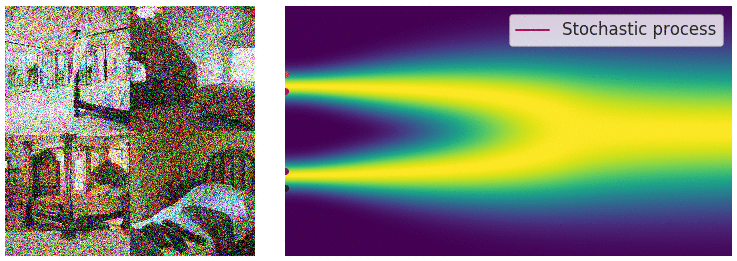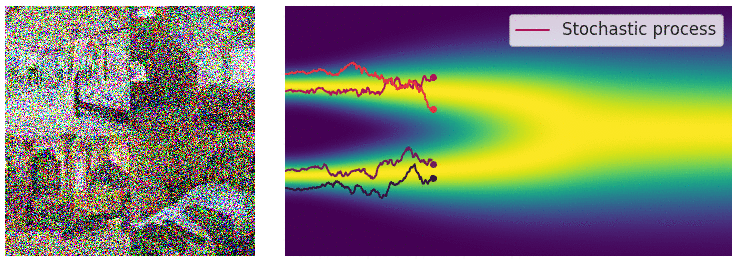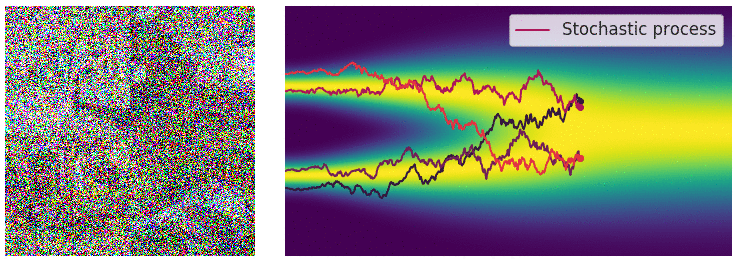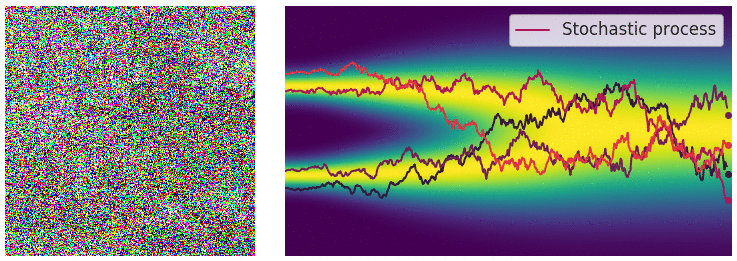
扩散模型的灵感来自非平衡热力学。它提出了一种以小步长迭代地将马尔可夫链的输出视为模型对学习分布的近似 ,以缓慢地将随机噪声添加到样本中,然后学习逆向扩散过程,从而根据噪声构建所需的数据样本。
与 VAE 或流模型不同,扩散模型是通过固定程序学习的,并且隐变量具有高维度(与原始样本 相同)。
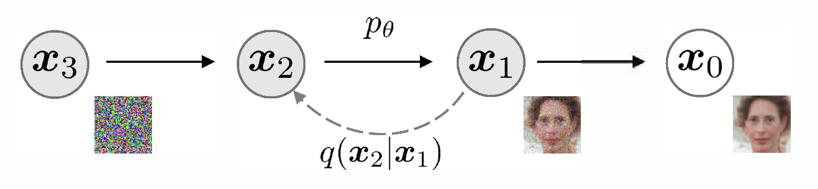
去噪扩散概率模型机制 ¶ 去噪扩散概率模型 ( Denoising Diffusion Probabilistic Models , DDPM )的机制
正向过程用于生成建模,通过逐步添加高斯噪声将样本(如图像、文本)降级至类似随机噪声状态。数学上,每一步由高斯转换内核定义,按预定方差增加噪声。随着噪声增加,样本结构减少,趋近纯噪声。此过程旨在构建从原始样本到简单先验分布的映射,以支持逆向的去噪和重建过程。
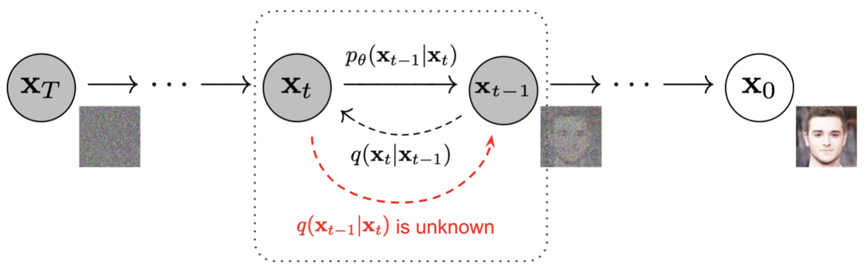
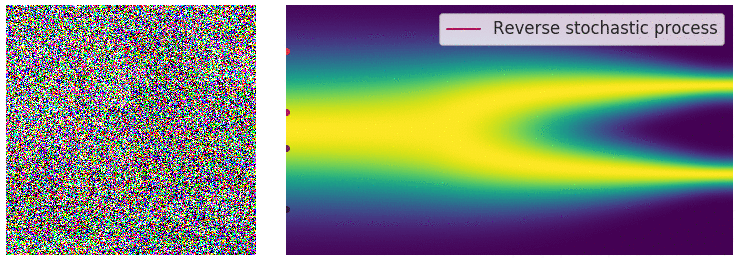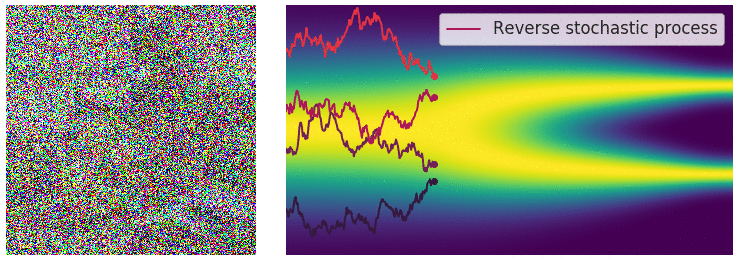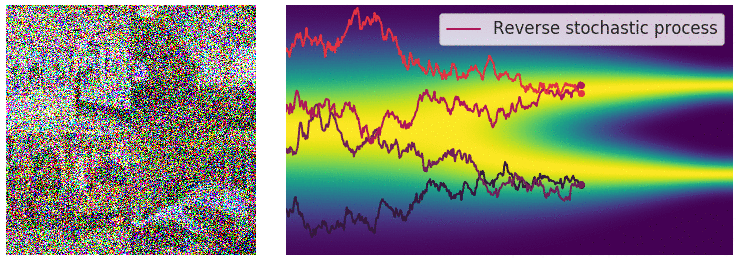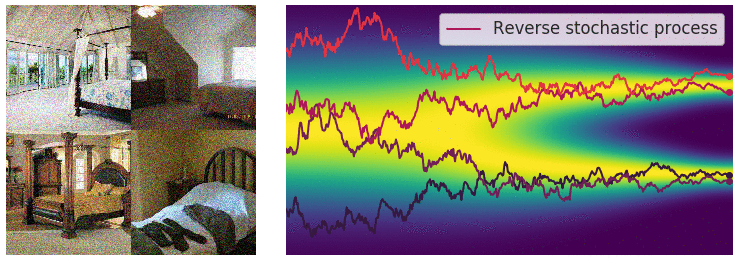
逆向过程利用神经网络从噪声中逐步去噪以重建样本,模拟正向过程的逆向操作。神经网络学习去除噪声分量,通过分数匹配 (Score Matching) 或变分推理等技术优化输出。逆向迭代去噪步骤生成高质量样本,使模型能将噪声转化为连贯结构化的输出,极大增强了生成模型的能力。
正向扩散过程 ¶ 给定初始的样本分布 x 0 ∼ q ( x 0 ) x_0 \sim q(x_0) x 0 ∼ q ( x 0 ) x 1 , x 2 , … , x T x_1, x_2, \dots, x_T x 1 , x 2 , … , x T
步长由方差调度超参数 β t ∈ [ 0 , 1 ) \beta_t \in [0, 1) β t ∈ [ 0 , 1 )
重复这个过程 T T T
当 T T T
转移概率 (transition probability) q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I ) q(\mathbf{x}_t | \mathbf{x}_{t-1}) = \mathcal{N}(\mathbf{x}_t; \sqrt{1-\beta_t}\mathbf{x}_{t-1}, \beta_t \mathbf{I}) q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I ) q ( x 1 : T | x 0 ) = ∏ t = 1 T q ( x t | x t − 1 ) q\left(\mathbf{x}_{1:T}\middle|\mathbf{x}_0\right)=\prod_{t=1}^{T}{q\left(\mathbf{x}_t\middle|\mathbf{x}_{t-1}\right)} q ( x 1 : T ∣ x 0 ) = ∏ t = 1 T q ( x t ∣ x t − 1 )
重新参数化技巧 ¶ 上述过程有一个很好的特性是我们可以在任意时间步对 x t \mathbf{x}_t x t α t = 1 − β t \alpha_t=1-\beta_t α t = 1 − β t α ‾ t = ∏ i = 1 t α i {\overline{\alpha}}_t=\prod_{i=1}^{t}\alpha_i α t = ∏ i = 1 t α i
q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I ) x t = α t x t − 1 + 1 − α t ϵ t − 1 where ϵ t − 1 , ϵ t − 2 , ⋯ ∼ N ( 0 , I ) = α t α t − 1 x t − 2 + 1 − α t α t − 1 ϵ t − 2 where ϵ t − 2 merges two Gaussians. = ⋯ = α ˉ t x 0 + 1 − α ˉ t ϵ q ( x t ∣ x 0 ) = N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) \begin{align}
q(\mathbf{x}_t|\mathbf{x}_{t-1}) &= \mathcal{N}(\mathbf{x}_t; \sqrt{1-\beta_t}\mathbf{x}_{t-1}, \beta_t \mathbf{I}) \\
\mathbf{x}_t &= \sqrt{\alpha_t}\mathbf{x}_{t-1} + \sqrt{1-\alpha_t}\boldsymbol{\epsilon}_{t-1} \quad \text{where } \boldsymbol{\epsilon}_{t-1}, \boldsymbol{\epsilon}_{t-2}, \cdots \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) \\
&= \sqrt{\alpha_t\alpha_{t-1}}\mathbf{x}_{t-2} + \sqrt{1-\alpha_t\alpha_{t-1}}\boldsymbol{\epsilon}_{t-2} \quad \text{where } \boldsymbol{\epsilon}_{t-2} \text{ merges two Gaussians.} \\
&= \cdots \\
&= \color{blue}{\sqrt{\bar{\alpha}_t}\mathbf{x}_0 + \sqrt{1-\bar{\alpha}_t}\boldsymbol{\epsilon}} \\
\color{red}{q(\mathbf{x}_t|\mathbf{x}_0)} &= \color{red}{\mathcal{N}(\mathbf{x}_t; \sqrt{\bar{\alpha}_t}\mathbf{x}_0, (1-\bar{\alpha}_t)\mathbf{I})}
\end{align} q ( x t ∣ x t − 1 ) x t q ( x t ∣ x 0 ) = N ( x t ; 1 − β t x t − 1 , β t I ) = α t x t − 1 + 1 − α t ϵ t − 1 where ϵ t − 1 , ϵ t − 2 , ⋯ ∼ N ( 0 , I ) = α t α t − 1 x t − 2 + 1 − α t α t − 1 ϵ t − 2 where ϵ t − 2 merges two Gaussians. = ⋯ = α ˉ t x 0 + 1 − α ˉ t ϵ = N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) 任意时刻的 q ( x t ) q\left(\mathbf{x}_t\right) q ( x t ) x 0 \mathbf{x}_0 x 0 β t \beta_t β t
根据正态分布的叠加性:两个正态分布 X ∼ N ( μ 1 , σ 1 2 ) X\sim \mathcal{N}\left(\mu_1,\sigma_1^2\right) X ∼ N ( μ 1 , σ 1 2 ) Y ∼ N ( μ 2 , σ 2 2 ) Y\sim \mathcal{N}\left(\mu_2,\sigma_2^2\right) Y ∼ N ( μ 2 , σ 2 2 ) a X + b Y aX+bY a X + bY a μ 1 + b μ 2 a\mu_1+b\mu_2 a μ 1 + b μ 2 a 2 σ 1 2 + b 2 σ 2 2 a^2\sigma_1^2+b^2\sigma_2^2 a 2 σ 1 2 + b 2 σ 2 2
叠加后的标准方差为 σ = ( 1 − α t ) + α t ( 1 − α t − 1 ) = 1 − α t α t − 1 \sigma=\sqrt{(1-\alpha_t)+\alpha_t(1-\alpha_{t-1})}=\sqrt{1-\alpha_t\alpha_{t-1}} σ = ( 1 − α t ) + α t ( 1 − α t − 1 ) = 1 − α t α t − 1
令 α t = 1 − β t \alpha_t = 1 - \beta_t α t = 1 − β t α ‾ t = ∏ i = 1 t α i {\overline{\alpha}}_t = \prod_{i=1}^t \alpha_i α t = ∏ i = 1 t α i x t = α ‾ t x 0 + 1 − α ‾ t ϵ \mathbf{x}_t = \sqrt{{\overline{\alpha}}_t}\mathbf{x}_0 + \sqrt{1-{\overline{\alpha}}_t}\boldsymbol{\epsilon} x t = α t x 0 + 1 − α t ϵ α t \alpha_t α t α t \alpha_t α t β t \beta_t β t T T T α t \alpha_t α t α t = 1 − 0.02 t T \alpha_t = \sqrt{1-\frac{0.02t}{T}} α t = 1 − T 0.02 t
计算 log α T \log \alpha_T log α T t = T t = T t = T
log α T = 1 2 log ( 1 − 0.02 T T ) = 1 2 log ( 0.98 ) \log \alpha_T = \frac{1}{2}\log\left(1-\frac{0.02T}{T}\right) = \frac{1}{2}\log(0.98) log α T = 2 1 log ( 1 − T 0.02 T ) = 2 1 log ( 0.98 ) 根据泰勒展开,对于 0 < x < 1 0 < x < 1 0 < x < 1 log ( 1 − x ) < − x \log(1-x) < -x log ( 1 − x ) < − x
log α t = 1 2 log ( 1 − 0.02 t T ) < − 0.01 t T \log \alpha_t = \frac{1}{2}\log\left(1-\frac{0.02t}{T}\right) < -\frac{0.01 t}{T} log α t = 2 1 log ( 1 − T 0.02 t ) < − T 0.01 t 所以当 T = 1000 T=1000 T = 1000 α T ≈ e − 5 ≈ 0 \alpha_T \approx e^{-5} \approx 0 α T ≈ e − 5 ≈ 0 x T = α ‾ T x 0 + 1 − α ‾ T ϵ ≈ ϵ ∼ N ( 0 , I ) \mathbf{x}_T = \sqrt{{\overline{\alpha}}_T}\mathbf{x}_0 + \sqrt{1-{\overline{\alpha}}_T}\boldsymbol{\epsilon} \approx \boldsymbol{\epsilon} \sim \mathcal{N}(0, I) x T = α T x 0 + 1 − α T ϵ ≈ ϵ ∼ N ( 0 , I )
逆向过程 ¶ 如果能够逆正向过程,并从 q ( x t − 1 ∣ x t ) q(\mathbf{x}_{t-1}|\mathbf{x}_t) q ( x t − 1 ∣ x t ) x T ∼ N ( 0 , I ) \mathbf{x}_T\sim\mathcal{N}(\mathbf{0},\mathbf{I}) x T ∼ N ( 0 , I ) β t \beta_t β t q ( x t − 1 ∣ x t ) q(\mathbf{x}_{t-1}|\mathbf{x}_t) q ( x t − 1 ∣ x t ) q ( x t − 1 | x t ) q\left(\mathbf{x}_{t-1}\middle|\mathbf{x}_t\right) q ( x t − 1 ∣ x t ) p θ p_\theta p θ
p θ ( x 0 : T ) = p ( x T ) ∏ t = 1 T p θ ( x t − 1 | x t ) p θ ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ θ ( x t , t ) , Σ θ ( x t , t ) ) \begin{align}
p_\theta\left(\mathbf{x}_{0:T}\right) &= p\left(\mathbf{x}_T\right)\prod_{t=1}^{T}{p_\theta\left(\mathbf{x}_{t-1}\middle|\mathbf{x}_t\right)} \\
p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_t) &= \mathcal{N}(\mathbf{x}_{t-1};\color{blue}{\boldsymbol{\mu}_\theta(\mathbf{x}_t,t),\boldsymbol{\Sigma}_\theta(\mathbf{x}_t,t)})
\end{align} p θ ( x 0 : T ) p θ ( x t − 1 ∣ x t ) = p ( x T ) t = 1 ∏ T p θ ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ θ ( x t , t ) , Σ θ ( x t , t ) ) 扩散模型的目标是学习逆向降噪过程,以迭代地去除正向过程中添加的噪声,逆过程也可以理解为从随机噪声中生成新样本,以 \color{blue}{\text{以}} 以 x 0 \color{blue}{\mathbf{x}_0} x 0 已知为条件时,逆向条件概率 \color{blue}{\text{已知为条件时,逆向条件概率}} 已知为条件时,逆向条件概率 q ( x t − 1 | x t , x 0 ) \color{blue}{q\left(\mathbf{x}_{t-1}\middle|\mathbf{x}_t,\mathbf{x}_0\right)} q ( x t − 1 ∣ x t , x 0 ) 是可解的。 \color{blue}{\text{是可解的。}} 是可解的。
q ( x t − 1 | x t , x 0 ) = N ( x t − 1 ; μ ~ ( x t , x 0 ) , β ~ t I ) q\left(\mathbf{x}_{t-1}\middle|\mathbf{x}_t,\mathbf{x}_0\right)=\mathcal{N}\left(\mathbf{x}_{t-1};\color{blue}{\tilde{\boldsymbol{\mu}}\left(\mathbf{x}_t,\mathbf{x}_0\right),\tilde{\beta}_t\mathbf{I}}\right) q ( x t − 1 ∣ x t , x 0 ) = N ( x t − 1 ; μ ~ ( x t , x 0 ) , β ~ t I ) 根据联合概率公式:
q ( x t − 1 | x t , x 0 ) q ( x t | x 0 ) = q ( x t , x t − 1 | x 0 ) = q ( x t | x t − 1 , x 0 ) q ( x t − 1 | x 0 ) q\left(\mathbf{x}_{t-1}\middle|\mathbf{x}_t,\mathbf{x}_0\right)q\left(\mathbf{x}_t\middle|\mathbf{x}_0\right)=q\left(\mathbf{x}_t,\mathbf{x}_{t-1}\middle|\mathbf{x}_0\right)=q\left(\mathbf{x}_t\middle|\mathbf{x}_{t-1},\mathbf{x}_0\right)q\left(\mathbf{x}_{t-1}\middle|\mathbf{x}_0\right) q ( x t − 1 ∣ x t , x 0 ) q ( x t ∣ x 0 ) = q ( x t , x t − 1 ∣ x 0 ) = q ( x t ∣ x t − 1 , x 0 ) q ( x t − 1 ∣ x 0 ) 我们有:
q ( x t − 1 | x t , x 0 ) = q ( x t | x t − 1 , x 0 ) q ( x t − 1 | x 0 ) q ( x t | x 0 ) \begin{align}
q\left(\mathbf{x}_{t-1}\middle|\mathbf{x}_t,\mathbf{x}_0\right) &= q\left(\mathbf{x}_t\middle|\mathbf{x}_{t-1},\mathbf{x}_0\right)\frac{q\left(\mathbf{x}_{t-1}\middle|\mathbf{x}_0\right)}{q\left(\mathbf{x}_t\middle|\mathbf{x}_0\right)}
\end{align} q ( x t − 1 ∣ x t , x 0 ) = q ( x t ∣ x t − 1 , x 0 ) q ( x t ∣ x 0 ) q ( x t − 1 ∣ x 0 ) 因为正向过程是马尔科夫链,x t \mathbf{x}_t x t x t − 1 \mathbf{x}_{t-1} x t − 1
q ( x t | x t − 1 , x 0 ) = q ( x t | x t − 1 ) q\left(\mathbf{x}_t\middle|\mathbf{x}_{t-1},\mathbf{x}_0\right)=q\left(\mathbf{x}_t\middle|\mathbf{x}_{t-1}\right) q ( x t ∣ x t − 1 , x 0 ) = q ( x t ∣ x t − 1 ) 代入上式得:
q ( x t − 1 | x t , x 0 ) = q ( x t | x t − 1 ) q ( x t − 1 | x 0 ) q ( x t | x 0 ) \begin{align}
q\left(\mathbf{x}_{t-1}\middle|\mathbf{x}_t,\mathbf{x}_0\right) &= q\left(\mathbf{x}_t\middle|\mathbf{x}_{t-1}\right)\frac{q\left(\mathbf{x}_{t-1}\middle|\mathbf{x}_0\right)}{q\left(\mathbf{x}_t\middle|\mathbf{x}_0\right)}
\end{align} q ( x t − 1 ∣ x t , x 0 ) = q ( x t ∣ x t − 1 ) q ( x t ∣ x 0 ) q ( x t − 1 ∣ x 0 ) 根据前向过程的定义,我们有:
q ( x t | x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I ) q\left(\mathbf{x}_t\middle|\mathbf{x}_{t-1}\right)=\mathcal{N}\left(\mathbf{x}_t;\sqrt{1-\beta_t}\mathbf{x}_{t-1},\beta_t\mathbf{I}\right) q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I )
q ( x t ∣ x 0 ) = N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) q(\mathbf{x}_t|\mathbf{x}_0)=\mathcal{N}\left(\mathbf{x}_t;\sqrt{\bar{\alpha}_t}\mathbf{x}_0,\left(1-\bar{\alpha}_t\right)\mathbf{I}\right) q ( x t ∣ x 0 ) = N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) 将以上高斯分布代入,得到:
q ( x t − 1 | x t , x 0 ) = N ( x t ; 1 − β t x t − 1 , β t I ) N ( x t − 1 ; α ˉ t − 1 x 0 , ( 1 − α ˉ t − 1 ) I ) N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) \begin{align}
q\left(\mathbf{x}_{t-1}\middle|\mathbf{x}_t,\mathbf{x}_0\right) &= \mathcal{N}\left(\mathbf{x}_t;\sqrt{1-\beta_t}\mathbf{x}_{t-1},\beta_t\mathbf{I}\right)\frac{\mathcal{N}\left(\mathbf{x}_{t-1};\sqrt{\bar{\alpha}_{t-1}}\mathbf{x}_0,\left(1-\bar{\alpha}_{t-1}\right)\mathbf{I}\right)}{\mathcal{N}\left(\mathbf{x}_t;\sqrt{\bar{\alpha}_t}\mathbf{x}_0,\left(1-\bar{\alpha}_t\right)\mathbf{I}\right)}
\end{align} q ( x t − 1 ∣ x t , x 0 ) = N ( x t ; 1 − β t x t − 1 , β t I ) N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) N ( x t − 1 ; α ˉ t − 1 x 0 , ( 1 − α ˉ t − 1 ) I ) 将各项代入高斯分布的概率密度函数 f ( x ) = 1 2 π σ e − ( x − μ ) 2 σ 2 f(x)=\frac{1}{\sqrt{2\pi\sigma}}e^{-\frac{(x-\mu)^2}{\sigma^2}} f ( x ) = 2 πσ 1 e − σ 2 ( x − μ ) 2
q ( x t − 1 | x t , x 0 ) = N ( x t ; 1 − β t x t − 1 , β t I ) N ( x t − 1 ; α ˉ t − 1 x 0 , ( 1 − α ˉ t − 1 ) I ) N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) ∝ exp ( − 1 2 ( ( x t − α t x t − 1 ) 2 β t + ( x t − 1 − α ˉ t − 1 x 0 ) 2 1 − α ˉ t − 1 − ( x t − α ˉ t x 0 ) 2 1 − α ˉ t ) ) = exp ( − 1 2 ( x t 2 − 2 α t x t x t − 1 + α t x t − 1 2 β t + x t − 1 2 − 2 α ˉ t − 1 x 0 x t − 1 + α ˉ t − 1 x 0 2 1 − α ˉ t − 1 − ( x t − α ˉ t x 0 ) 2 1 − α ˉ t ) ) = exp ( − 1 2 ( ( α t β t + 1 1 − α ˉ t − 1 ) x t − 1 2 − ( 2 α t β t x t + 2 α ˉ t − 1 1 − α ˉ t − 1 x 0 ) x t − 1 + C ( x t , x 0 ) ) ) \begin{align}
q\left(\mathbf{x}_{t-1}\middle|\mathbf{x}_t,\mathbf{x}_0\right) &= \mathcal{N}\left(\mathbf{x}_t;\sqrt{1-\beta_t}\mathbf{x}_{t-1},\beta_t\mathbf{I}\right)\frac{\mathcal{N}\left(\mathbf{x}_{t-1};\sqrt{\bar{\alpha}_{t-1}}\mathbf{x}_0,\left(1-\bar{\alpha}_{t-1}\right)\mathbf{I}\right)}{\mathcal{N}\left(\mathbf{x}_t;\sqrt{\bar{\alpha}_t}\mathbf{x}_0,\left(1-\bar{\alpha}_t\right)\mathbf{I}\right)} \\
&\propto\exp{\left(-\frac{1}{2}\left(\frac{(\mathbf{x}_t-\sqrt{\alpha_t}\mathbf{x}_{t-1})^2}{\beta_t}+\frac{(\mathbf{x}_{t-1}-\sqrt{\bar{\alpha}_{t-1}}\mathbf{x}_0)^2}{1-\bar{\alpha}_{t-1}}-\frac{(\mathbf{x}_t-\sqrt{\bar{\alpha}_t}\mathbf{x}_0)^2}{1-\bar{\alpha}_t}\right)\right)} \\
&= \exp\left(-\frac{1}{2}\left(\frac{\mathbf{x}_t^2-2\sqrt{\alpha_t}\mathbf{x}_t\mathbf{x}_{t-1}+\alpha_t\mathbf{x}_{t-1}^2}{\beta_t}+\frac{\mathbf{x}_{t-1}^2-2\sqrt{\bar{\alpha}_{t-1}}\mathbf{x}_0\mathbf{x}_{t-1}+\bar{\alpha}_{t-1}\mathbf{x}_0^2}{1-\bar{\alpha}_{t-1}}-\frac{(\mathbf{x}_t-\sqrt{\bar{\alpha}_t}\mathbf{x}_0)^2}{1-\bar{\alpha}_t}\right)\right) \\
&= \exp\left(-\frac{1}{2}\left(\left(\frac{\alpha_t}{\beta_t}+\frac{1}{1-\bar{\alpha}_{t-1}}\right)\mathbf{x}_{t-1}^2-\left(\frac{2\sqrt{\alpha_t}}{\beta_t}\mathbf{x}_t+\frac{2\sqrt{\bar{\alpha}_{t-1}}}{1-\bar{\alpha}_{t-1}}\mathbf{x}_0\right)\mathbf{x}_{t-1}+C\left(\mathbf{x}_t,\mathbf{x}_0\right)\right)\right)
\end{align} q ( x t − 1 ∣ x t , x 0 ) = N ( x t ; 1 − β t x t − 1 , β t I ) N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) N ( x t − 1 ; α ˉ t − 1 x 0 , ( 1 − α ˉ t − 1 ) I ) ∝ exp ( − 2 1 ( β t ( x t − α t x t − 1 ) 2 + 1 − α ˉ t − 1 ( x t − 1 − α ˉ t − 1 x 0 ) 2 − 1 − α ˉ t ( x t − α ˉ t x 0 ) 2 ) ) = exp ( − 2 1 ( β t x t 2 − 2 α t x t x t − 1 + α t x t − 1 2 + 1 − α ˉ t − 1 x t − 1 2 − 2 α ˉ t − 1 x 0 x t − 1 + α ˉ t − 1 x 0 2 − 1 − α ˉ t ( x t − α ˉ t x 0 ) 2 ) ) = exp ( − 2 1 ( ( β t α t + 1 − α ˉ t − 1 1 ) x t − 1 2 − ( β t 2 α t x t + 1 − α ˉ t − 1 2 α ˉ t − 1 x 0 ) x t − 1 + C ( x t , x 0 ) ) ) 其中 C ( x t , x 0 ) C(\mathbf{x}_t,\mathbf{x}_0) C ( x t , x 0 ) x t − 1 \mathbf{x}_{t-1} x t − 1
多元高斯分布可以表达为 exp ( − 1 2 x T A x + b T x + c ) \exp{\left(-\frac{1}{2}\mathbf{x}^TA\mathbf{x}+b^T\mathbf{x}+c\right)} exp ( − 2 1 x T A x + b T x + c ) Σ = A − 1 \mathbf{\Sigma}=A^{-1} Σ = A − 1 μ = A − 1 b \boldsymbol{\mu}=A^{-1}b μ = A − 1 b
exp ( − 1 2 ( ( α t β t + 1 1 − α ˉ t − 1 ) x t − 1 2 − ( 2 α t β t x t + 2 α ˉ t − 1 1 − α ˉ t − 1 x 0 ) x t − 1 + C ( x t , x 0 ) ) ) \exp\left(-\frac{1}{2}\left(\left(\frac{\alpha_t}{\beta_t}+\frac{1}{1-\bar{\alpha}_{t-1}}\right)\mathbf{x}_{t-1}^2-\left(\frac{2\sqrt{\alpha_t}}{\beta_t}\mathbf{x}_t+\frac{2\sqrt{\bar{\alpha}_{t-1}}}{1-\bar{\alpha}_{t-1}}\mathbf{x}_0\right)\mathbf{x}_{t-1}+C\left(\mathbf{x}_t,\mathbf{x}_0\right)\right)\right) exp ( − 2 1 ( ( β t α t + 1 − α ˉ t − 1 1 ) x t − 1 2 − ( β t 2 α t x t + 1 − α ˉ t − 1 2 α ˉ t − 1 x 0 ) x t − 1 + C ( x t , x 0 ) ) ) β ~ t = Σ = A − 1 = 1 α t β t + 1 1 − α ˉ t − 1 = 1 − α ˉ t − 1 1 − α ˉ t ⋅ β t \tilde{\beta}_t=\mathbf{\Sigma}=A^{-1}=\frac{1}{\frac{\alpha_t}{\beta_t}+\frac{1}{1-\bar{\alpha}_{t-1}}}=\frac{1-\bar{\alpha}_{t-1}}{1-\bar{\alpha}_t}\cdot\beta_t β ~ t = Σ = A − 1 = β t α t + 1 − α ˉ t − 1 1 1 = 1 − α ˉ t 1 − α ˉ t − 1 ⋅ β t μ ~ t ( x t , x 0 ) = A − 1 b = α t ( 1 − α ˉ t − 1 ) 1 − α ˉ t x t + α ˉ t − 1 β t 1 − α ˉ t x 0 \tilde{\boldsymbol{\mu}}_t\left(\mathbf{x}_t,\mathbf{x}_0\right)=A^{-1}b=\frac{\sqrt{\alpha_t}(1-\bar{\alpha}_{t-1})}{1-\bar{\alpha}_t}\mathbf{x}_t+\frac{\sqrt{\bar{\alpha}_{t-1}}\beta_t}{1-\bar{\alpha}_t}\mathbf{x}_0 μ ~ t ( x t , x 0 ) = A − 1 b = 1 − α ˉ t α t ( 1 − α ˉ t − 1 ) x t + 1 − α ˉ t α ˉ t − 1 β t x 0 因为 x t = α ˉ t x 0 + 1 − α ˉ t ϵ ⇒ x 0 = 1 α ˉ t ( x t − 1 − α ˉ t ϵ t ) \mathbf{x}_t=\sqrt{\bar{\alpha}_t}\mathbf{x}_0+\sqrt{1-\bar{\alpha}_t}\boldsymbol{\epsilon} \Rightarrow \mathbf{x}_0=\frac{1}{\sqrt{\bar{\alpha}_t}}(\mathbf{x}_t-\sqrt{1-\bar{\alpha}_t}\boldsymbol{\epsilon}_t) x t = α ˉ t x 0 + 1 − α ˉ t ϵ ⇒ x 0 = α ˉ t 1 ( x t − 1 − α ˉ t ϵ t )
μ ~ t = 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ t ) \tilde{\boldsymbol{\mu}}_t=\frac{1}{\sqrt{\alpha_t}}(\mathbf{x}_t-\frac{1-\alpha_t}{\sqrt{1-\bar{\alpha}_t}}\boldsymbol{\epsilon}_t) μ ~ t = α t 1 ( x t − 1 − α ˉ t 1 − α t ϵ t ) 最后的表达式就为:
q ( x t − 1 | x t , x 0 ) = N ( x t − 1 ; μ ~ t , β ~ t I ) = N ( x t − 1 ; 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ t ) , 1 − α ˉ t − 1 1 − α ˉ t ⋅ β t I ) q\left(\mathbf{x}_{t-1}\middle|\mathbf{x}_t,\mathbf{x}_0\right)=\mathcal{N}\left(\mathbf{x}_{t-1};\color{blue}{\tilde{\boldsymbol{\mu}}_t,\tilde{\beta}_t\mathbf{I}} \right)=\mathcal{N}\left(\mathbf{x}_{t-1};\frac{1}{\sqrt{\alpha_t}}(\mathbf{x}_t-\frac{1-\alpha_t}{\sqrt{1-\bar{\alpha}_t}}\boldsymbol{\epsilon}_t),\frac{1-\bar{\alpha}_{t-1}}{1-\bar{\alpha}_t}\cdot\beta_t\mathbf{I}\right) q ( x t − 1 ∣ x t , x 0 ) = N ( x t − 1 ; μ ~ t , β ~ t I ) = N ( x t − 1 ; α t 1 ( x t − 1 − α ˉ t 1 − α t ϵ t ) , 1 − α ˉ t 1 − α ˉ t − 1 ⋅ β t I ) 损失函数与变分下界 ¶ 目标是学习 μ ~ ( x t , x 0 ) \tilde{\boldsymbol{\mu}}\left(\mathbf{x}_t,\mathbf{x}_0\right) μ ~ ( x t , x 0 ) β ~ t \tilde{\beta}_t β ~ t
H ( q ( x 0 ) , p θ ( x 0 ) ) = − ∫ q ( x 0 ) log p θ ( x 0 ) d x 0 = − E q ( x 0 ) log p θ ( x 0 ) = − E q ( x 0 ) log ( ∫ p θ ( x 0 : T ) d x 1 : T ) = − E q ( x 0 ) log ( ∫ q ( x 1 : T | x 0 ) p θ ( x 0 : T ) q ( x 1 : T | x 0 ) d x 1 : T ) = − E q ( x 0 ) log ( E q ( x 1 : T | x 0 ) p θ ( x 0 : T ) q ( x 1 : T | x 0 ) ) \begin{align}
H\left(q\left(x_0\right),p_\theta\left(x_0\right)\right) &= -\int{q\left(x_0\right)\log{p_\theta\left(x_0\right)}dx_0} \\
&= -\mathbb{E}_{q\left(\mathbf{x}_0\right)}\log{p_\theta\left(\mathbf{x}_0\right)} \\
&= -\mathbb{E}_{q\left(\mathbf{x}_0\right)}\log{\left(\int{p_\theta\left(\mathbf{x}_{0:T}\right)d\mathbf{x}_{1:T}}\right)} \\
&= -\mathbb{E}_{q\left(\mathbf{x}_0\right)}\log{\left(\int{q\left(\mathbf{x}_{1:T}\middle|\mathbf{x}_0\right)\frac{p_\theta\left(\mathbf{x}_{0:T}\right)}{q\left(\mathbf{x}_{1:T}\middle|\mathbf{x}_0\right)}d\mathbf{x}_{1:T}}\right)} \\
&= -\mathbb{E}_{q\left(\mathbf{x}_0\right)}\log{\left(\mathbb{E}_{q\left(\mathbf{x}_{1:T}\middle|\mathbf{x}_0\right)}\frac{p_\theta\left(\mathbf{x}_{0:T}\right)}{q\left(\mathbf{x}_{1:T}\middle|\mathbf{x}_0\right)}\right)}
\end{align} H ( q ( x 0 ) , p θ ( x 0 ) ) = − ∫ q ( x 0 ) log p θ ( x 0 ) d x 0 = − E q ( x 0 ) log p θ ( x 0 ) = − E q ( x 0 ) log ( ∫ p θ ( x 0 : T ) d x 1 : T ) = − E q ( x 0 ) log ( ∫ q ( x 1 : T ∣ x 0 ) q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) d x 1 : T ) = − E q ( x 0 ) log ( E q ( x 1 : T ∣ x 0 ) q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) ) 对于凸函数,我们可以运用詹森不等式(Jensen’s inequality),f ( E [ X ] ) ≤ E [ f ( X ) ] f(\mathbb{E}[X])\leq\mathbb{E}[f(X)] f ( E [ X ]) ≤ E [ f ( X )] − log -\log − log
H ( q ( x 0 ) , p θ ( x 0 ) ) ≤ − E q ( x 0 : T ) log p θ ( x 0 : T ) q ( x 1 : T | x 0 ) Negative ELBO 是一个上界 \begin{align}
H\left(q\left(x_0\right),p_\theta\left(x_0\right)\right) &\le -\mathbb{E}_{q\left(\mathbf{x}_{0:T}\right)}\log{\frac{p_\theta\left(\mathbf{x}_{0:T}\right)}{q\left(\mathbf{x}_{1:T}\middle|\mathbf{x}_0\right)}} \quad \color{blue}{\text{Negative ELBO 是一个上界}}
\end{align} H ( q ( x 0 ) , p θ ( x 0 ) ) ≤ − E q ( x 0 : T ) log q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) Negative ELBO 是一个上界 L N E L B O = E q ( x 0 : T ) log q ( x 1 : T | x 0 ) p θ ( x 0 : T ) L_{\mathrm{NELBO}}=\mathbb{E}_{q(\mathbf{x}_{0:T})}\log{\frac{q\left(\mathbf{x}_{1:T}\middle|\mathbf{x}_0\right)}{p_\theta\left(\mathbf{x}_{0:T}\right)}} L NELBO = E q ( x 0 : T ) log p θ ( x 0 : T ) q ( x 1 : T ∣ x 0 ) q ( x 0 : T ) = q ( x 1 : T | x 0 ) q ( x 0 ) q\left(\mathbf{x}_{0:T}\right)=q\left(\mathbf{x}_{1:T}\middle|\mathbf{x}_0\right)q\left(\mathbf{x}_0\right) q ( x 0 : T ) = q ( x 1 : T ∣ x 0 ) q ( x 0 ) 展开 L N E L B O L_{\mathrm{NELBO}} L NELBO
L N E L B O = E q ( x 0 : T ) [ log q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) ] = E q [ log ∏ t = 1 T q ( x t ∣ x t − 1 ) p θ ( x T ) ∏ t = 1 T p θ ( x t − 1 ∣ x t ) ] \begin{aligned}
L_{\mathrm{NELBO}} &= \mathbb{E}_{q\left(\mathbf{x}_{0:T}\right)}\left[\log \frac{q\left(\mathbf{x}_{1:T} \mid \mathbf{x}_0\right)}{p_\theta\left(\mathbf{x}_{0:T}\right)}\right] = \mathbb{E}_q\left[\log \frac{\prod_{t=1}^T q\left(\mathbf{x}_t \mid \mathbf{x}_{t-1}\right)}{p_\theta\left(\mathbf{x}_T\right) \prod_{t=1}^T p_\theta\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t\right)}\right]
\end{aligned} L NELBO = E q ( x 0 : T ) [ log p θ ( x 0 : T ) q ( x 1 : T ∣ x 0 ) ] = E q [ log p θ ( x T ) ∏ t = 1 T p θ ( x t − 1 ∣ x t ) ∏ t = 1 T q ( x t ∣ x t − 1 ) ] 对数乘法变加法 :
= E q [ − log p θ ( x T ) + ∑ t = 1 T log q ( x t ∣ x t − 1 ) p θ ( x t − 1 ∣ x t ) ] \begin{aligned}
&= \mathbb{E}_q\left[-\log p_\theta\left(\mathbf{x}_T\right)+\sum_{t=1}^T \log \frac{q\left(\mathbf{x}_t \mid \mathbf{x}_{t-1}\right)}{p_\theta\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t\right)}\right]
\end{aligned} = E q [ − log p θ ( x T ) + t = 1 ∑ T log p θ ( x t − 1 ∣ x t ) q ( x t ∣ x t − 1 ) ] t = 1 t=1 t = 1
= E q [ − log p θ ( x T ) + ∑ t = 2 T log q ( x t ∣ x t − 1 ) p θ ( x t − 1 ∣ x t ) + log q ( x 1 ∣ x 0 ) p θ ( x 0 ∣ x 1 ) ] \begin{aligned}
&= \mathbb{E}_q\left[-\log p_\theta\left(\mathbf{x}_T\right)+\sum_{t=2}^T \log \frac{q\left(\mathbf{x}_t \mid \mathbf{x}_{t-1}\right)}{p_\theta\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t\right)}+\log \frac{q\left(\mathbf{x}_1 \mid \mathbf{x}_0\right)}{p_\theta\left(\mathbf{x}_0 \mid \mathbf{x}_1\right)}\right]
\end{aligned} = E q [ − log p θ ( x T ) + t = 2 ∑ T log p θ ( x t − 1 ∣ x t ) q ( x t ∣ x t − 1 ) + log p θ ( x 0 ∣ x 1 ) q ( x 1 ∣ x 0 ) ] 根据贝叶斯公式 q ( x t | x t − 1 ) = q ( x t − 1 ∣ x t ) q ( x t ) q ( x t − 1 ) q\left(\mathbf{x}_t\middle|\mathbf{x}_{t-1}\right)=\frac{q\left(\mathbf{x}_{t-1}|\mathbf{x}_t\right)q\left(\mathbf{x}_t\right)}{q\left(\mathbf{x}_{t-1}\right)} q ( x t ∣ x t − 1 ) = q ( x t − 1 ) q ( x t − 1 ∣ x t ) q ( x t ) :
= E q [ − log p θ ( x T ) + ∑ t = 2 T log ( q ( x t − 1 ∣ x t ) p θ ( x t − 1 ∣ x t ) ⋅ q ( x t ) q ( x t − 1 ) ) + log q ( x 1 ∣ x 0 ) p θ ( x 0 ∣ x 1 ) ] \begin{aligned}
&= \mathbb{E}_q\left[-\log p_\theta\left(\mathbf{x}_T\right)+\sum_{t=2}^T \log \left(\frac{q\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t\right)}{p_\theta\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t\right)} \cdot \frac{q\left(\mathbf{x}_t \right)}{q\left(\mathbf{x}_{t-1} \right)}\right)+\log \frac{q\left(\mathbf{x}_1 \mid \mathbf{x}_0\right)}{p_\theta\left(\mathbf{x}_0 \mid \mathbf{x}_1\right)}\right]
\end{aligned} = E q [ − log p θ ( x T ) + t = 2 ∑ T log ( p θ ( x t − 1 ∣ x t ) q ( x t − 1 ∣ x t ) ⋅ q ( x t − 1 ) q ( x t ) ) + log p θ ( x 0 ∣ x 1 ) q ( x 1 ∣ x 0 ) ] 对每一项概率添加 x 0 \mathbf{x}_0 x 0 :
= E q [ − log p θ ( x T ) + ∑ t = 2 T log ( q ( x t − 1 ∣ x t , x 0 ) p θ ( x t − 1 ∣ x t ) ⋅ q ( x t ∣ x 0 ) q ( x t − 1 ∣ x 0 ) ) + log q ( x 1 ∣ x 0 ) p θ ( x 0 ∣ x 1 ) ] \begin{aligned}
&= \mathbb{E}_q\left[-\log p_\theta\left(\mathbf{x}_T\right)+\sum_{t=2}^T \log \left(\frac{q\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t, \mathbf{x}_0\right)}{p_\theta\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t\right)} \cdot \frac{q\left(\mathbf{x}_t \mid \mathbf{x}_0\right)}{q\left(\mathbf{x}_{t-1} \mid \mathbf{x}_0\right)}\right)+\log \frac{q\left(\mathbf{x}_1 \mid \mathbf{x}_0\right)}{p_\theta\left(\mathbf{x}_0 \mid \mathbf{x}_1\right)}\right]
\end{aligned} = E q [ − log p θ ( x T ) + t = 2 ∑ T log ( p θ ( x t − 1 ∣ x t ) q ( x t − 1 ∣ x t , x 0 ) ⋅ q ( x t − 1 ∣ x 0 ) q ( x t ∣ x 0 ) ) + log p θ ( x 0 ∣ x 1 ) q ( x 1 ∣ x 0 ) ] 对数乘法再次变加法:
= E q [ − log p θ ( x T ) + ∑ t = 2 T log q ( x t − 1 ∣ x t , x 0 ) p θ ( x t − 1 ∣ x t ) + ∑ t = 2 T log q ( x t ∣ x 0 ) q ( x t − 1 ∣ x 0 ) + log q ( x 1 ∣ x 0 ) p θ ( x 0 ∣ x 1 ) ] \begin{aligned}
&= \mathbb{E}_q\left[-\log p_\theta\left(\mathbf{x}_T\right)+\sum_{t=2}^T \log \frac{q\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t, \mathbf{x}_0\right)}{p_\theta\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t\right)}+\sum_{t=2}^T \log \frac{q\left(\mathbf{x}_t \mid \mathbf{x}_0\right)}{q\left(\mathbf{x}_{t-1} \mid \mathbf{x}_0\right)}+\log \frac{q\left(\mathbf{x}_1 \mid \mathbf{x}_0\right)}{p_\theta\left(\mathbf{x}_0 \mid \mathbf{x}_1\right)}\right]
\end{aligned} = E q [ − log p θ ( x T ) + t = 2 ∑ T log p θ ( x t − 1 ∣ x t ) q ( x t − 1 ∣ x t , x 0 ) + t = 2 ∑ T log q ( x t − 1 ∣ x 0 ) q ( x t ∣ x 0 ) + log p θ ( x 0 ∣ x 1 ) q ( x 1 ∣ x 0 ) ] 分子与分母展开,只有第一项 t = 1 t=1 t = 1 t = T t=T t = T (telescoping sum):
= E q [ − log p θ ( x T ) + ∑ t = 2 T log q ( x t − 1 ∣ x t , x 0 ) p θ ( x t − 1 ∣ x t ) + log q ( x T ∣ x 0 ) q ( x 1 ∣ x 0 ) + log q ( x 1 ∣ x 0 ) p θ ( x 0 ∣ x 1 ) ] \begin{aligned}
&= \mathbb{E}_q\left[-\log p_\theta\left(\mathbf{x}_T\right)+\sum_{t=2}^T \log \frac{q\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t, \mathbf{x}_0\right)}{p_\theta\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t\right)}+\log \frac{q\left(\mathbf{x}_T \mid \mathbf{x}_0\right)}{q\left(\mathbf{x}_1 \mid \mathbf{x}_0\right)}+\log \frac{q\left(\mathbf{x}_1 \mid \mathbf{x}_0\right)}{p_\theta\left(\mathbf{x}_0 \mid \mathbf{x}_1\right)}\right]
\end{aligned} = E q [ − log p θ ( x T ) + t = 2 ∑ T log p θ ( x t − 1 ∣ x t ) q ( x t − 1 ∣ x t , x 0 ) + log q ( x 1 ∣ x 0 ) q ( x T ∣ x 0 ) + log p θ ( x 0 ∣ x 1 ) q ( x 1 ∣ x 0 ) ] 再做合并与消除简化 :
= E q [ log q ( x T ∣ x 0 ) p θ ( x T ) + ∑ t = 2 T log q ( x t − 1 ∣ x t , x 0 ) p θ ( x t − 1 ∣ x t ) − log p θ ( x 0 ∣ x 1 ) ] \begin{aligned}
&= \mathbb{E}_q\left[\log \frac{q\left(\mathbf{x}_T \mid \mathbf{x}_0\right)}{p_\theta\left(\mathbf{x}_T\right)}+\sum_{t=2}^T \log \frac{q\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t, \mathbf{x}_0\right)}{p_\theta\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t\right)}-\log p_\theta\left(\mathbf{x}_0 \mid \mathbf{x}_1\right)\right]
\end{aligned} = E q [ log p θ ( x T ) q ( x T ∣ x 0 ) + t = 2 ∑ T log p θ ( x t − 1 ∣ x t ) q ( x t − 1 ∣ x t , x 0 ) − log p θ ( x 0 ∣ x 1 ) ] 根据双重期望定理 E [ E [ X ∣ Y ] ] = E [ X ] \mathbb{E}\left[\mathbb{E}\left[X|Y\right]\right]=\mathbb{E}[X] E [ E [ X ∣ Y ] ] = E [ X ]
= E q [ E q ( x T ∣ x 0 ) [ log q ( x T ∣ x 0 ) p θ ( x T ) ] + ∑ t = 2 T E q ( x t − 1 ∣ x t , x 0 ) [ log q ( x t − 1 ∣ x t , x 0 ) p θ ( x t − 1 ∣ x t ) ] − log p θ ( x 0 ∣ x 1 ) ] \begin{aligned}
&= \mathbb{E}_q\left[\mathbb{E}_{q\left(\mathbf{x}_T \mid \mathbf{x}_0\right)}\left[\log \frac{q\left(\mathbf{x}_T \mid \mathbf{x}_0\right)}{p_\theta\left(\mathbf{x}_T\right)}\right]+\sum_{t=2}^T \mathbb{E}_{q\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t, \mathbf{x}_0\right)}\left[\log \frac{q\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t, \mathbf{x}_0\right)}{p_\theta\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t\right)}\right]-\log p_\theta\left(\mathbf{x}_0 \mid \mathbf{x}_1\right)\right]
\end{aligned} = E q [ E q ( x T ∣ x 0 ) [ log p θ ( x T ) q ( x T ∣ x 0 ) ] + t = 2 ∑ T E q ( x t − 1 ∣ x t , x 0 ) [ log p θ ( x t − 1 ∣ x t ) q ( x t − 1 ∣ x t , x 0 ) ] − log p θ ( x 0 ∣ x 1 ) ] 根据 KL 散度的定义 D K L ( p ∥ q ) = E p [ log p q ] D_{KL}(p\|q) = \mathbb{E}_p\left[\log \frac{p}{q}\right] D K L ( p ∥ q ) = E p [ log q p ]
L N E L B O = E q [ D K L ( q ( x T ∣ x 0 ) ∥ p θ ( x T ) ) ⏟ L T + ∑ t = 2 T D K L ( q ( x t − 1 ∣ x t , x 0 ) ∥ p θ ( x t − 1 ∣ x t ) ) ⏟ L t − 1 − log p θ ( x 0 ∣ x 1 ) ⏟ L 0 ] \begin{aligned}
L_{\mathrm{NELBO}} &= \mathbb{E}_q\left[\underbrace{D_{KL}\left(q\left(\mathbf{x}_T \mid \mathbf{x}_0\right) \| p_\theta\left(\mathbf{x}_T\right)\right)}_{L_T}+\sum_{t=2}^T \underbrace{D_{KL}\left(q\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t, \mathbf{x}_0\right) \| p_\theta\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t\right)\right)}_{L_{t-1}}-\underbrace{\log p_\theta\left(\mathbf{x}_0 \mid \mathbf{x}_1\right)}_{L_0}\right]
\end{aligned} L NELBO = E q ⎣ ⎡ L T D K L ( q ( x T ∣ x 0 ) ∥ p θ ( x T ) ) + t = 2 ∑ T L t − 1 D K L ( q ( x t − 1 ∣ x t , x 0 ) ∥ p θ ( x t − 1 ∣ x t ) ) − L 0 log p θ ( x 0 ∣ x 1 ) ⎦ ⎤ 其中 L T L_T L T θ \theta θ L 0 L_0 L 0 t = 1 t=1 t = 1 N ( x 0 ; μ θ ( x 1 , 1 ) , σ 1 2 I ) \mathcal{N}\left(\mathbf{x}_0;\boldsymbol{\mu}_\theta\left(\mathbf{x}_1,1\right),\sigma_1^2\mathbf{I}\right) N ( x 0 ; μ θ ( x 1 , 1 ) , σ 1 2 I ) x 0 i x_0^i x 0 i [ σ − ( x 0 i ) , σ + ( x 0 i ) ] [\sigma_-\left(x_0^i\right),\sigma_+\left(x_0^i\right)] [ σ − ( x 0 i ) , σ + ( x 0 i ) ] μ θ ( x 1 , 1 ) \boldsymbol{\mu}_\theta\left(\mathbf{x}_1,1\right) μ θ ( x 1 , 1 ) x 0 i x_0^i x 0 i
L 0 = log p θ ( x 0 | x 1 ) = ∑ i D log ( ∫ σ − ( x 0 i ) σ + ( x 0 i ) N ( x ; μ θ ( x 1 , 1 ) , σ 1 2 I ) d x ) L_0=\log{p_\theta}\left(\mathbf{x}_0\middle|\mathbf{x}_1\right)=\sum_{i}^{D}\log{\left(\int_{\sigma_-\left(x_0^i\right)}^{\sigma_+\left(x_0^i\right)}\mathcal{N}\left(x;\boldsymbol{\mu}_\theta\left(\mathbf{x}_1,1\right),\sigma_1^2\mathbf{I}\right)dx\right)} L 0 = log p θ ( x 0 ∣ x 1 ) = i ∑ D log ( ∫ σ − ( x 0 i ) σ + ( x 0 i ) N ( x ; μ θ ( x 1 , 1 ) , σ 1 2 I ) d x ) σ + ( x ) = { ∞ , if x = 1 x + 1 255 , if x < 1 σ − ( x ) = { − ∞ , if x = − 1 x − 1 255 , if x > − 1 \sigma_{+}(x)=\begin{cases}
\infty, & \text{if } x=1 \\
x+\frac{1}{255}, & \text{if } x<1
\end{cases} \quad \sigma_{-}(x)= \begin{cases}-\infty, & \text{if } x=-1 \\
x-\frac{1}{255}, & \text{if } x>-1\end{cases} σ + ( x ) = { ∞ , x + 255 1 , if x = 1 if x < 1 σ − ( x ) = { − ∞ , x − 255 1 , if x = − 1 if x > − 1 L t − 1 = D K L ( q ( x t − 1 | x t , x 0 ) ∥ p θ ( x t − 1 | x t ) ) L_{t-1}=D_{\mathrm{KL}}\left(q\left(\mathbf{x}_{t-1}\middle|\mathbf{x}_t,\mathbf{x}_0\right)\parallel p_\theta\left(\mathbf{x}_{t-1}\middle|\mathbf{x}_t\right)\right) L t − 1 = D KL ( q ( x t − 1 ∣ x t , x 0 ) ∥ p θ ( x t − 1 ∣ x t ) )
真实后验分布(已知 x 0 \mathbf{x}_0 x 0 x t \mathbf{x}_t x t x t − 1 \mathbf{x}_{t-1} x t − 1
q ( x t − 1 | x t , x 0 ) = N ( x t − 1 ; μ ~ t , β ~ t I ) = N ( x t − 1 ; 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ t ) , 1 − α ˉ t − 1 1 − α ˉ t ⋅ β t I ) q\left(\mathbf{x}_{t-1}\middle|\mathbf{x}_t,\mathbf{x}_0\right)=\mathcal{N}\left(\mathbf{x}_{t-1};\tilde{\boldsymbol{\mu}}_t,\tilde{\beta}_t\mathbf{I}\right)=\mathcal{N}\left(\mathbf{x}_{t-1};\frac{1}{\sqrt{\alpha_t}}\left(\mathbf{x}_t-\frac{1-\alpha_t}{\sqrt{1-\bar{\alpha}_t}}\boldsymbol{\epsilon}_t\right),\frac{1-\bar{\alpha}_{t-1}}{1-\bar{\alpha}_t}\cdot\beta_t\mathbf{I}\right) q ( x t − 1 ∣ x t , x 0 ) = N ( x t − 1 ; μ ~ t , β ~ t I ) = N ( x t − 1 ; α t 1 ( x t − 1 − α ˉ t 1 − α t ϵ t ) , 1 − α ˉ t 1 − α ˉ t − 1 ⋅ β t I ) 模型预测的逆向分布采样公式(需要学习的分布)为:
p θ ( x t − 1 | x t ) = N ( x t − 1 ; μ θ ( x t , t ) , Σ θ ( x t , t ) ) = N ( x t − 1 ; 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ θ ( x t , t ) ) , β t I ) \color{blue}{
p_\theta\left(\mathbf{x}_{t-1}\middle|\mathbf{x}_t\right)
=\mathcal{N}\left(\mathbf{x}_{t-1};\,\boldsymbol{\mu}_\theta\left(\mathbf{x}_t,t\right),\,\boldsymbol{\Sigma}_\theta\left(\mathbf{x}_t,t\right)\right)
=\mathcal{N}\left(\mathbf{x}_{t-1};\,\frac{1}{\sqrt{\alpha_t}}\left(\mathbf{x}_t-\frac{1-\alpha_t}{\sqrt{1-\bar{\alpha}_t}}\,\boldsymbol{\epsilon}_\theta(\mathbf{x}_t,t)\right),\,\beta_t\mathbf{I}\right)
} p θ ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ θ ( x t , t ) , Σ θ ( x t , t ) ) = N ( x t − 1 ; α t 1 ( x t − 1 − α ˉ t 1 − α t ϵ θ ( x t , t ) ) , β t I ) 由于两者都是高斯分布,我们可以利用高斯分布 KL 散度的解析形式来计算:
K L ( N ( μ 1 , Σ 1 2 ) ∥ N ( μ 2 , Σ 2 2 ) ) = 1 2 ( log Σ 2 2 − log Σ 1 2 + Σ 1 2 + ( μ 1 − μ 2 ) 2 Σ 2 2 − 1 ) \mathrm{KL}\left(\mathcal{N}\left(\boldsymbol{\mu}_1,\boldsymbol{\Sigma}_1^2\right)\parallel\mathcal{N}\left(\boldsymbol{\mu}_2,\boldsymbol{\Sigma}_2^2\right)\right)=\frac{1}{2}\left(\log\boldsymbol{\Sigma}_2^2-\log\boldsymbol{\Sigma}_1^2+\frac{\boldsymbol{\Sigma}_1^2+\left(\boldsymbol{\mu}_1-\boldsymbol{\mu}_2\right)^2}{\boldsymbol{\Sigma}_2^2}-1\right) KL ( N ( μ 1 , Σ 1 2 ) ∥ N ( μ 2 , Σ 2 2 ) ) = 2 1 ( log Σ 2 2 − log Σ 1 2 + Σ 2 2 Σ 1 2 + ( μ 1 − μ 2 ) 2 − 1 ) 简化的损失函数:预测噪声 ¶ 因为 β t \beta_t β t ϵ \boldsymbol{\epsilon} ϵ
L t − 1 = E x 0 , ϵ [ 1 2 ∥ Σ θ ( x t , t ) ∥ 2 2 ∥ μ ~ t ( x t , x 0 ) − μ θ ( x t , t ) ∥ 2 ] = E x 0 , ϵ [ 1 2 ∥ Σ θ ∥ 2 2 ∥ 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ t ) − 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ θ ( x t , t ) ) ∥ 2 ] = E x 0 , ϵ [ ( 1 − α t ) 2 2 α t ( 1 − α ˉ t ) ∥ Σ θ ∥ 2 2 ∥ ϵ t − ϵ θ ( x t , t ) ∥ 2 ] = E x 0 , ϵ [ ( 1 − α t ) 2 2 α t ( 1 − α ˉ t ) ∥ Σ θ ∥ 2 2 ∥ ϵ t − ϵ θ ( α ˉ t x 0 + 1 − α ˉ t ϵ t , t ) ∥ 2 ] \begin{aligned}
L_{t-1} &= \mathbb{E}_{\mathbf{x}_0,\boldsymbol{\epsilon}}\left[\frac{1}{2\|\boldsymbol{\Sigma}_\theta(\mathbf{x}_t,t)\|_2^2}\|\tilde{\boldsymbol{\mu}}_t(\mathbf{x}_t,\mathbf{x}_0)-\boldsymbol{\mu}_\theta(\mathbf{x}_t,t)\|^2\right] \\
&= \mathbb{E}_{\mathbf{x}_0,\boldsymbol{\epsilon}}\left[\frac{1}{2\|\boldsymbol{\Sigma}_\theta\|_2^2}\left\|\frac{1}{\sqrt{\alpha_t}}\left(\mathbf{x}_t-\frac{1-\alpha_t}{\sqrt{1-\bar{\alpha}_t}}\boldsymbol{\epsilon}_t\right)-\frac{1}{\sqrt{\alpha_t}}\left(\mathbf{x}_t-\frac{1-\alpha_t}{\sqrt{1-\bar{\alpha}_t}}\boldsymbol{\epsilon}_\theta(\mathbf{x}_t,t)\right)\right\|^2\right] \\
&= \mathbb{E}_{\mathbf{x}_0,\boldsymbol{\epsilon}}\left[\frac{(1-\alpha_t)^2}{2\alpha_t(1-\bar{\alpha}_t)\|\boldsymbol{\Sigma}_\theta\|_2^2}\|\boldsymbol{\epsilon}_t-\boldsymbol{\epsilon}_\theta(\mathbf{x}_t,t)\|^2\right] \\
&= \mathbb{E}_{\mathbf{x}_0,\boldsymbol{\epsilon}}\left[\frac{(1-\alpha_t)^2}{2\alpha_t(1-\bar{\alpha}_t)\|\boldsymbol{\Sigma}_\theta\|_2^2}\|\boldsymbol{\epsilon}_t-\boldsymbol{\epsilon}_\theta(\sqrt{\bar{\alpha}_t}\mathbf{x}_0+\sqrt{1-\bar{\alpha}_t}\boldsymbol{\epsilon}_t,t)\|^2\right]
\end{aligned} L t − 1 = E x 0 , ϵ [ 2∥ Σ θ ( x t , t ) ∥ 2 2 1 ∥ μ ~ t ( x t , x 0 ) − μ θ ( x t , t ) ∥ 2 ] = E x 0 , ϵ [ 2∥ Σ θ ∥ 2 2 1 ∥ ∥ α t 1 ( x t − 1 − α ˉ t 1 − α t ϵ t ) − α t 1 ( x t − 1 − α ˉ t 1 − α t ϵ θ ( x t , t ) ) ∥ ∥ 2 ] = E x 0 , ϵ [ 2 α t ( 1 − α ˉ t ) ∥ Σ θ ∥ 2 2 ( 1 − α t ) 2 ∥ ϵ t − ϵ θ ( x t , t ) ∥ 2 ] = E x 0 , ϵ [ 2 α t ( 1 − α ˉ t ) ∥ Σ θ ∥ 2 2 ( 1 − α t ) 2 ∥ ϵ t − ϵ θ ( α ˉ t x 0 + 1 − α ˉ t ϵ t , t ) ∥ 2 ] 最终发现忽略权重结果更好,这不再是对数似然的变分下界。
L t − 1 s i m p l e = E t ∼ [ 1 , T ] , x 0 , ϵ t [ ∥ ϵ t − ϵ θ ( x t , t ) ∥ 2 ] = E t ∼ [ 1 , T ] , x 0 , ϵ t [ ∥ ϵ t − ϵ θ ( α ˉ t x 0 + 1 − α ˉ t ϵ t , t ) ∥ 2 ] + C \begin{aligned}
L_{t-1}^{\mathrm{simple}} &= \mathbb{E}_{t\sim[1,T],\mathbf{x}_0,\boldsymbol{\epsilon}_t}\left[\|\boldsymbol{\epsilon}_t-\boldsymbol{\epsilon}_\theta(\mathbf{x}_t,t)\|^2\right] \\
&= \mathbb{E}_{t\sim[1,T],\mathbf{x}_0,\boldsymbol{\epsilon}_t}\left[\|\boldsymbol{\epsilon}_t-\boldsymbol{\epsilon}_\theta(\sqrt{\bar{\alpha}_t}\mathbf{x}_0+\sqrt{1-\bar{\alpha}_t}\boldsymbol{\epsilon}_t,t)\|^2\right]+C
\end{aligned} L t − 1 simple = E t ∼ [ 1 , T ] , x 0 , ϵ t [ ∥ ϵ t − ϵ θ ( x t , t ) ∥ 2 ] = E t ∼ [ 1 , T ] , x 0 , ϵ t [ ∥ ϵ t − ϵ θ ( α ˉ t x 0 + 1 − α ˉ t ϵ t , t ) ∥ 2 ] + C DDPM 训练算法 ¶ Algorithm 1: Training repeat x 0 ∼ q ( x 0 ) 从数据分布中采样 t ∼ Uniform ( { 1 , … , T } ) 随机选择时间步 ϵ ∼ N ( 0 , I ) 采样高斯噪声 梯度下降更新: ∇ θ ∥ ϵ − ϵ θ ( α ˉ t x 0 + 1 − α ˉ t ϵ , t ) ∥ 2 until converged \begin{array}{l}
\textbf{Algorithm 1: Training} \\
\hline
\textbf{repeat} \\
\quad \mathbf{x}_0 \sim q(\mathbf{x}_0) \quad \text{从数据分布中采样} \\
\quad t \sim \text{Uniform}(\{1, \ldots, T\}) \quad \text{随机选择时间步} \\
\quad \boldsymbol{\epsilon} \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) \quad \text{采样高斯噪声} \\
\quad \text{梯度下降更新: } \nabla_\theta \left\|\boldsymbol{\epsilon} - \boldsymbol{\epsilon}_\theta\left(\sqrt{\bar{\alpha}_t}\mathbf{x}_0 + \sqrt{1-\bar{\alpha}_t}\boldsymbol{\epsilon}, t\right)\right\|^2 \\
\textbf{until converged}
\end{array} Algorithm 1: Training repeat x 0 ∼ q ( x 0 ) 从数据分布中采样 t ∼ Uniform ({ 1 , … , T }) 随机选择时间步 ϵ ∼ N ( 0 , I ) 采样高斯噪声 梯度下降更新 : ∇ θ ∥ ∥ ϵ − ϵ θ ( α ˉ t x 0 + 1 − α ˉ t ϵ , t ) ∥ ∥ 2 until converged DDPM 采样算法(根据逆向分布采样公式) ¶ Algorithm 2: Sampling x T ∼ N ( 0 , I ) 从纯噪声开始 for t = T , … , 1 do z ∼ N ( 0 , I ) if t > 1 , else z = 0 x t − 1 = 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ θ ( x t , t ) ) + σ t z end for return x 0 \begin{array}{l}
\textbf{Algorithm 2: Sampling} \\
\hline
\mathbf{x}_T \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) \quad \text{从纯噪声开始} \\
\textbf{for } t = T, \ldots, 1 \textbf{ do} \\
\quad \mathbf{z} \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) \text{ if } t > 1 \text{, else } \mathbf{z} = \mathbf{0} \\
\quad \mathbf{x}_{t-1} = \frac{1}{\sqrt{\alpha_t}}\left(\mathbf{x}_t - \frac{1-\alpha_t}{\sqrt{1-\bar{\alpha}_t}}\boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t)\right) + \sigma_t\mathbf{z} \\
\textbf{end for} \\
\textbf{return } \mathbf{x}_0
\end{array} Algorithm 2: Sampling x T ∼ N ( 0 , I ) 从纯噪声开始 for t = T , … , 1 do z ∼ N ( 0 , I ) if t > 1 , else z = 0 x t − 1 = α t 1 ( x t − 1 − α ˉ t 1 − α t ϵ θ ( x t , t ) ) + σ t z end for return x 0 其中 σ t = 1 − α ˉ t − 1 1 − α ˉ t ⋅ β t \sigma_t = \sqrt{\frac{1-\bar{\alpha}_{t-1}}{1-\bar{\alpha}_t} \cdot \beta_t} σ t = 1 − α ˉ t 1 − α ˉ t − 1 ⋅ β t
训练算法的核心思想是:对于每个训练样本,随机选择一个时间步 t t t x t \mathbf{x}_t x t ϵ \boldsymbol{\epsilon} ϵ
采样算法则从纯噪声 x T \mathbf{x}_T x T x 0 \mathbf{x}_0 x 0
图像生成的扩散模型 ¶ 正向过程:将图像分布转换为纯噪声
逆过程:从图像分布中采样,从纯噪声开始
扩散加速:去噪扩散隐式模型(DDIM) ¶ DDPM马尔可夫链模型
DDIM非马尔可夫链模型
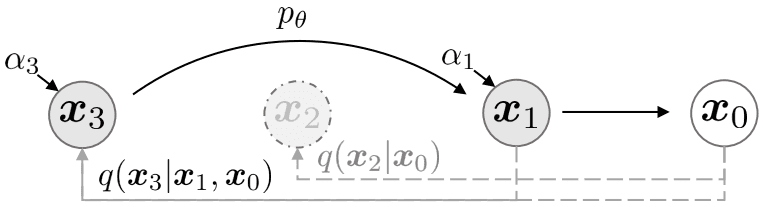
当采用基于逆向扩散过程的马尔可夫链DDPM生成样本时,由于迭代次数可达几千步,生成速度相对较慢。为了加速采样,去噪扩散隐式模型(Denoising Diffusion Implicit Models, DDIM)提出了一类更高效的迭代隐式概率模型。
马尔可夫 vs 非马尔可夫:为什么 DDIM 可以跳步? ¶ DDPM(马尔可夫过程)的限制:
在 DDPM 中,正向扩散过程定义为马尔可夫链,即 x t \mathbf{x}_t x t 仅依赖于 x t − 1 \mathbf{x}_{t-1} x t − 1
q ( x t ∣ x t − 1 , x 0 ) = q ( x t ∣ x t − 1 ) q(\mathbf{x}_t | \mathbf{x}_{t-1}, \mathbf{x}_0) = q(\mathbf{x}_t | \mathbf{x}_{t-1}) q ( x t ∣ x t − 1 , x 0 ) = q ( x t ∣ x t − 1 ) 这意味着:给定 x t − 1 \mathbf{x}_{t-1} x t − 1 x 0 \mathbf{x}_0 x 0 x t \mathbf{x}_t x t x T → x T − 1 → ⋯ → x 1 → x 0 \mathbf{x}_T \to \mathbf{x}_{T-1} \to \cdots \to \mathbf{x}_1 \to \mathbf{x}_0 x T → x T − 1 → ⋯ → x 1 → x 0
DDIM(非马尔可夫过程)的突破:
DDIM 重新定义了正向过程,使 x t \mathbf{x}_t x t 同时依赖于 x t − 1 \mathbf{x}_{t-1} x t − 1 x 0 \mathbf{x}_0 x 0
q ( x t ∣ x t − 1 , x 0 ) ≠ q ( x t ∣ x t − 1 ) q(\mathbf{x}_t | \mathbf{x}_{t-1}, \mathbf{x}_0) \neq q(\mathbf{x}_t | \mathbf{x}_{t-1}) q ( x t ∣ x t − 1 , x 0 ) = q ( x t ∣ x t − 1 ) 关键在于:DDIM 构造的联合分布保持与 DDPM 相同的边际分布 q ( x t ∣ x 0 ) q(\mathbf{x}_t|\mathbf{x}_0) q ( x t ∣ x 0 ) q ( x t ∣ x t − 1 , x 0 ) q(\mathbf{x}_t|\mathbf{x}_{t-1}, \mathbf{x}_0) q ( x t ∣ x t − 1 , x 0 ) x 0 \mathbf{x}_0 x 0
为什么非马尔可夫允许跳步?
由于 DDPM 的训练目标仅依赖于边际分布 q ( x t ∣ x 0 ) q(\mathbf{x}_t|\mathbf{x}_0) q ( x t ∣ x 0 ) t t t q ( x 1 : T ∣ x 0 ) q(\mathbf{x}_{1:T}|\mathbf{x}_0) q ( x 1 : T ∣ x 0 )
复用相同的预训练模型 :神经网络 ϵ θ ( x t , t ) \boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t) ϵ θ ( x t , t ) x t \mathbf{x}_t x t
在任意子序列上采样 :逆向过程可以定义在时间步的子集 τ 1 , τ 2 , … , τ S \tau_1, \tau_2, \ldots, \tau_S τ 1 , τ 2 , … , τ S S ≪ T S \ll T S ≪ T
直接跳跃 :DDIM 的更新公式显式利用预测的 x ^ 0 \hat{\mathbf{x}}_0 x ^ 0 x t \mathbf{x}_t x t x ^ 0 \hat{\mathbf{x}}_0 x ^ 0 x s \mathbf{x}_s x s s < t s < t s < t
DDIM 推导 ¶ 接下来将可控噪声(标准偏差为 σ t \sigma_t σ t x t \mathbf{x}_t x t x t − 1 \mathbf{x}_{t-1} x t − 1 p θ ( x 0 : T ) p_\theta(\mathbf{x}_{0:T}) p θ ( x 0 : T ) p θ ( t ) ( x t − 1 ∣ x t ) p_\theta^{(t)}(\mathbf{x}_{t-1}|\mathbf{x}_t) p θ ( t ) ( x t − 1 ∣ x t ) q σ ( x t − 1 ∣ x t , x 0 ) q_\sigma(\mathbf{x}_{t-1}|\mathbf{x}_t,\mathbf{x}_0) q σ ( x t − 1 ∣ x t , x 0 ) x t \mathbf{x}_t x t x ^ 0 = f θ ( t ) ( x t ) \hat{\mathbf{x}}_0=f_\theta^{(t)}(\mathbf{x}_t) x ^ 0 = f θ ( t ) ( x t ) q σ ( x t − 1 ∣ x t , x ^ 0 ) q_\sigma(\mathbf{x}_{t-1}|\mathbf{x}_t,\hat{\mathbf{x}}_0) q σ ( x t − 1 ∣ x t , x ^ 0 ) x t − 1 \mathbf{x}_{t-1} x t − 1
由于重参数化,我们有:
x t = α ˉ t x 0 + 1 − α ˉ t ϵ ⇒ x 0 = x t − 1 − α ˉ t ϵ α ˉ t \mathbf{x}_t = \sqrt{\bar{\alpha}_t}\mathbf{x}_0 + \sqrt{1-\bar{\alpha}_t}\boldsymbol{\epsilon} \quad \Rightarrow \quad \mathbf{x}_0 = \frac{\mathbf{x}_t - \sqrt{1-\bar{\alpha}_t}\boldsymbol{\epsilon}}{\sqrt{\bar{\alpha}_t}} x t = α ˉ t x 0 + 1 − α ˉ t ϵ ⇒ x 0 = α ˉ t x t − 1 − α ˉ t ϵ 同理,对于 x t − 1 \mathbf{x}_{t-1} x t − 1
x t − 1 = α ˉ t − 1 x 0 + 1 − α ˉ t − 1 ϵ t − 1 \mathbf{x}_{t-1} = \sqrt{\bar{\alpha}_{t-1}}\mathbf{x}_0 + \sqrt{1-\bar{\alpha}_{t-1}}\boldsymbol{\epsilon}_{t-1} x t − 1 = α ˉ t − 1 x 0 + 1 − α ˉ t − 1 ϵ t − 1 其中,ϵ t − 1 \boldsymbol{\epsilon}_{t-1} ϵ t − 1 ϵ t \boldsymbol{\epsilon}_t ϵ t ϵ \boldsymbol{\epsilon} ϵ
ϵ t − 1 = 1 − α ˉ t − 1 − σ t 2 1 − α ˉ t − 1 ϵ t + σ t 1 − α ˉ t − 1 ϵ \boldsymbol{\epsilon}_{t-1} = \frac{\sqrt{1-\bar{\alpha}_{t-1}-\sigma_t^2}}{\sqrt{1-\bar{\alpha}_{t-1}}}\boldsymbol{\epsilon}_t + \frac{\sigma_t}{\sqrt{1-\bar{\alpha}_{t-1}}}\boldsymbol{\epsilon} ϵ t − 1 = 1 − α ˉ t − 1 1 − α ˉ t − 1 − σ t 2 ϵ t + 1 − α ˉ t − 1 σ t ϵ 将 x 0 \mathbf{x}_0 x 0 ϵ t − 1 \boldsymbol{\epsilon}_{t-1} ϵ t − 1
x t − 1 = α ˉ t − 1 x 0 + 1 − α ˉ t − 1 ϵ t − 1 = α ˉ t − 1 x 0 + 1 − α ˉ t − 1 − σ t 2 ϵ t + σ t ϵ = α ˉ t − 1 ⋅ x t − 1 − α ˉ t ϵ t α ˉ t + 1 − α ˉ t − 1 − σ t 2 ϵ t + σ t ϵ \begin{aligned}
\mathbf{x}_{t-1} &= \sqrt{\bar{\alpha}_{t-1}}\mathbf{x}_0 + \sqrt{1-\bar{\alpha}_{t-1}}\boldsymbol{\epsilon}_{t-1} \\
&= \sqrt{\bar{\alpha}_{t-1}}\mathbf{x}_0 + \sqrt{1-\bar{\alpha}_{t-1}-\sigma_t^2}\boldsymbol{\epsilon}_t + \sigma_t\boldsymbol{\epsilon} \\
&= \sqrt{\bar{\alpha}_{t-1}} \cdot \frac{\mathbf{x}_t - \sqrt{1-\bar{\alpha}_t}\boldsymbol{\epsilon}_t}{\sqrt{\bar{\alpha}_t}} + \sqrt{1-\bar{\alpha}_{t-1}-\sigma_t^2}\boldsymbol{\epsilon}_t + \sigma_t\boldsymbol{\epsilon}
\end{aligned} x t − 1 = α ˉ t − 1 x 0 + 1 − α ˉ t − 1 ϵ t − 1 = α ˉ t − 1 x 0 + 1 − α ˉ t − 1 − σ t 2 ϵ t + σ t ϵ = α ˉ t − 1 ⋅ α ˉ t x t − 1 − α ˉ t ϵ t + 1 − α ˉ t − 1 − σ t 2 ϵ t + σ t ϵ 在实际推断中,输入 x t \mathbf{x}_t x t ϵ θ ( t ) ( x t ) \boldsymbol{\epsilon}_\theta^{(t)}(\mathbf{x}_t) ϵ θ ( t ) ( x t ) ϵ t \boldsymbol{\epsilon}_t ϵ t
x ^ 0 = f θ ( t ) ( x t ) = x t − 1 − α ˉ t ϵ θ ( t ) ( x t ) α ˉ t \hat{\mathbf{x}}_0 = f_\theta^{(t)}(\mathbf{x}_t) = \frac{\mathbf{x}_t - \sqrt{1-\bar{\alpha}_t}\boldsymbol{\epsilon}_\theta^{(t)}(\mathbf{x}_t)}{\sqrt{\bar{\alpha}_t}} x ^ 0 = f θ ( t ) ( x t ) = α ˉ t x t − 1 − α ˉ t ϵ θ ( t ) ( x t ) 将预测的噪声代入 DDIM 更新公式,我们有:
x t − 1 = α ˉ t − 1 ⋅ x t − 1 − α ˉ t ϵ θ ( t ) ( x t ) α ˉ t + 1 − α ˉ t − 1 − σ t 2 ϵ θ ( t ) ( x t ) + σ t ϵ = α ˉ t − 1 x ^ 0 + 1 − α ˉ t − 1 − σ t 2 ϵ θ ( t ) ( x t ) + σ t ϵ \begin{aligned}
\mathbf{x}_{t-1} &= \sqrt{\bar{\alpha}_{t-1}} \cdot \frac{\mathbf{x}_t - \sqrt{1-\bar{\alpha}_t}\boldsymbol{\epsilon}_\theta^{(t)}(\mathbf{x}_t)}{\sqrt{\bar{\alpha}_t}} + \sqrt{1-\bar{\alpha}_{t-1}-\sigma_t^2}\boldsymbol{\epsilon}_\theta^{(t)}(\mathbf{x}_t) + \sigma_t\boldsymbol{\epsilon} \\
&= \sqrt{\bar{\alpha}_{t-1}}\hat{\mathbf{x}}_0 + \sqrt{1-\bar{\alpha}_{t-1}-\sigma_t^2}\boldsymbol{\epsilon}_\theta^{(t)}(\mathbf{x}_t) + \sigma_t\boldsymbol{\epsilon}
\end{aligned} x t − 1 = α ˉ t − 1 ⋅ α ˉ t x t − 1 − α ˉ t ϵ θ ( t ) ( x t ) + 1 − α ˉ t − 1 − σ t 2 ϵ θ ( t ) ( x t ) + σ t ϵ = α ˉ t − 1 x ^ 0 + 1 − α ˉ t − 1 − σ t 2 ϵ θ ( t ) ( x t ) + σ t ϵ 因此,逆向条件分布为:
q σ ( x t − 1 ∣ x t , x ^ 0 ) = N ( x t − 1 ; α ˉ t − 1 x ^ 0 + 1 − α ˉ t − 1 − σ t 2 ϵ θ ( t ) ( x t ) , σ t 2 I ) q_\sigma(\mathbf{x}_{t-1}|\mathbf{x}_t,\hat{\mathbf{x}}_0) = \mathcal{N}\left(\mathbf{x}_{t-1}; \sqrt{\bar{\alpha}_{t-1}}\hat{\mathbf{x}}_0 + \sqrt{1-\bar{\alpha}_{t-1}-\sigma_t^2}\boldsymbol{\epsilon}_\theta^{(t)}(\mathbf{x}_t), \sigma_t^2\mathbf{I}\right) q σ ( x t − 1 ∣ x t , x ^ 0 ) = N ( x t − 1 ; α ˉ t − 1 x ^ 0 + 1 − α ˉ t − 1 − σ t 2 ϵ θ ( t ) ( x t ) , σ t 2 I ) 生成过程被认为是逆过程的近似;由于正向过程有 T T T T T T q σ ( x t ∣ x 0 ) q_\sigma(\mathbf{x}_t|\mathbf{x}_0) q σ ( x t ∣ x 0 ) T T T t = 1 , … , T t=1,\ldots,T t = 1 , … , T s < t s < t s < t
σ t ( η ) = η ⋅ ( 1 − α ˉ t α ˉ s ) 1 − α ˉ s 1 − α ˉ t \sigma_t(\eta) = \eta \cdot \sqrt{\left(1-\frac{\bar{\alpha}_t}{\bar{\alpha}_s}\right)\frac{1-\bar{\alpha}_s}{1-\bar{\alpha}_t}} σ t ( η ) = η ⋅ ( 1 − α ˉ s α ˉ t ) 1 − α ˉ t 1 − α ˉ s q σ , s < t ( x s ∣ x t , x ^ 0 ) = N ( x s ; α ˉ s x ^ 0 + 1 − α ˉ s − σ t 2 ϵ θ ( t ) ( x t ) , σ t 2 I ) q_{\sigma, s < t}(\mathbf{x}_s | \mathbf{x}_t, \hat{\mathbf{x}}_0) = \mathcal{N}\left(\mathbf{x}_s; \sqrt{\bar{\alpha}_s} \hat{\mathbf{x}}_0 + \sqrt{1-\bar{\alpha}_s - \sigma_t^2} \, \boldsymbol{\epsilon}_\theta^{(t)}(\mathbf{x}_t), \sigma_t^2 \mathbf{I} \right) q σ , s < t ( x s ∣ x t , x ^ 0 ) = N ( x s ; α ˉ s x ^ 0 + 1 − α ˉ s − σ t 2 ϵ θ ( t ) ( x t ) , σ t 2 I ) 其中 η ∈ [ 0 , 1 ] \eta \in [0,1] η ∈ [ 0 , 1 ] η = 1 \eta=1 η = 1 η = 0 \eta=0 η = 0 σ t = 0 \sigma_t=0 σ t = 0 t ≠ 1 t \neq 1 t = 1 x t − 1 \mathbf{x}_{t-1} x t − 1 x 0 \mathbf{x}_0 x 0
与 DDPM 相比,DDIM 能够:
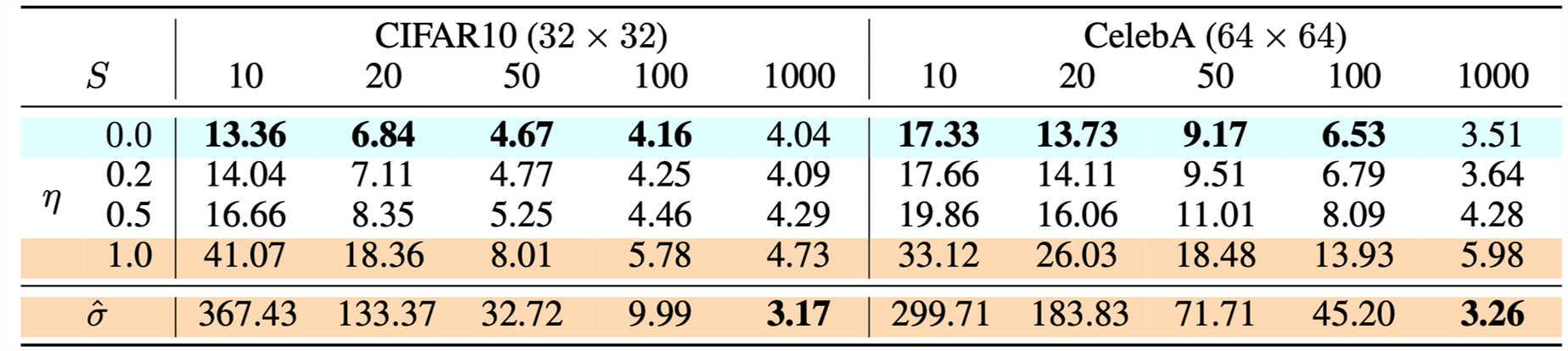
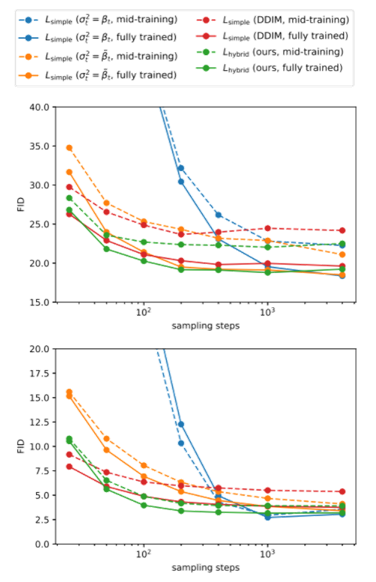
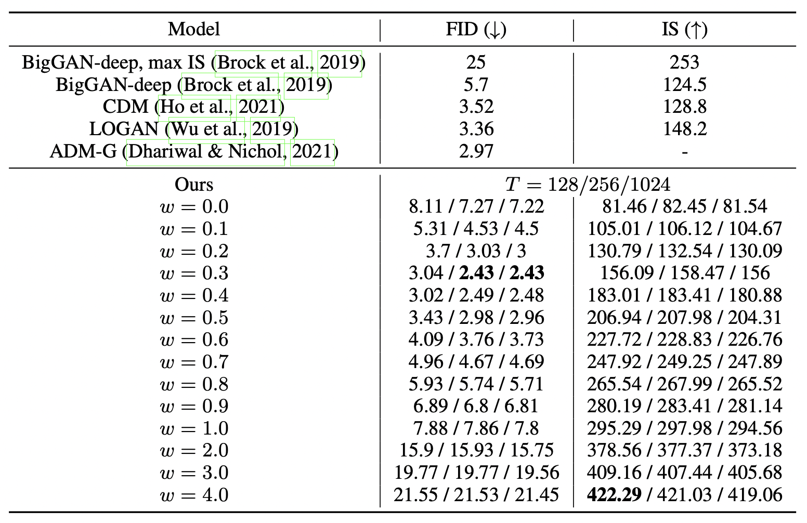
下图为不同设置的扩散模型在 CIFAR10 和 CelebA 数据集上的 FID 指标(Fréchet Inception Distance,数值越小越好):DDIM(η = 0 \eta=0 η = 0 σ ^ \hat{\sigma} σ ^ S S S
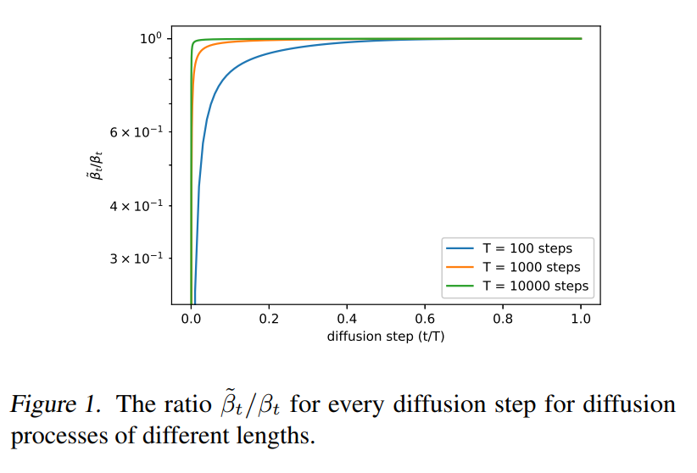
IDDPM改进:可学习的方差调度变量 ¶ 去噪扩散概率模型(DDPM)将正向过程中的方差 β t \beta_t β t β 1 = 1 0 − 4 \beta_1=10^{-4} β 1 = 1 0 − 4 β T = 0.02 \beta_T=0.02 β T = 0.02 [ − 1 , 1 ] [-1, 1] [ − 1 , 1 ] β t \beta_t β t
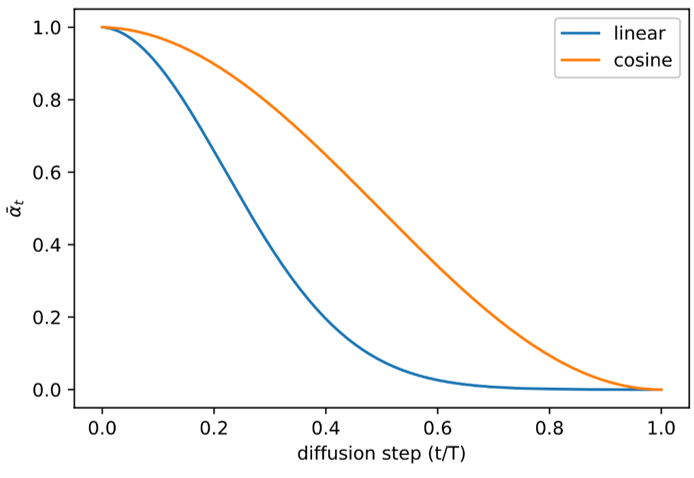
Nichol & Dhariwal (2021) 提出了一些改进技术,以帮助扩散模型获得更低的负对数似然值。其中一个重要改进就是采用基于余弦函数的方差调度。只要调度函数 f ( t ) f(t) f ( t ) t = 1 t=1 t = 1 t = T t=T t = T
β t = c l i p ( 1 − α ˉ t α ˉ t − 1 , 0 , 0.999 ) \beta_t = \mathrm{clip}\left( 1 - \frac{\bar{\alpha}_t}{\bar{\alpha}_{t-1}},\, 0,\, 0.999 \right) β t = clip ( 1 − α ˉ t − 1 α ˉ t , 0 , 0.999 ) α ˉ t = f ( t ) f ( 0 ) \bar{\alpha}_t = \frac{f(t)}{f(0)} α ˉ t = f ( 0 ) f ( t ) 其中 f ( t ) = cos 2 ( t T + s 1 + s ⋅ π 2 ) \text{其中} \quad f(t) = \cos^2\left( \frac{\frac{t}{T} + s}{1 + s} \cdot \frac{\pi}{2} \right) 其中 f ( t ) = cos 2 ( 1 + s T t + s ⋅ 2 π ) 其中偏置 s s s t = 0 t=0 t = 0
线性(上)与余弦(下)
学习协方差矩阵 ¶ 去噪扩散概率模型(DDPM)的研究发现,使用固定的协方差矩阵(例如 Σ θ ( x t , t ) = β t I \boldsymbol{\Sigma}_\theta(\mathbf{x}_t,t)=\beta_t\mathbf{I} Σ θ ( x t , t ) = β t I Σ θ ( x t , t ) = β ~ t I \boldsymbol{\Sigma}_\theta(\mathbf{x}_t,t)=\tilde{\beta}_t\mathbf{I} Σ θ ( x t , t ) = β ~ t I
β t I \beta_t\mathbf{I} β t I x 0 ∼ N ( 0 , I ) x_0 \sim \mathcal{N}(0, \mathbf{I}) x 0 ∼ N ( 0 , I )
β ~ t I \tilde{\beta}_t\mathbf{I} β ~ t I x 0 x_0 x 0
虽然固定方差在生成质量上表现不错,但实验表明学习协方差矩阵可以进一步提高对数似然值(Log-Likelihood)。Nichol & Dhariwal 提出了通过模型输出一个插值系数 v \mathbf{v} v Σ θ ( x t , t ) \boldsymbol{\Sigma}_\theta(\mathbf{x}_t,t) Σ θ ( x t , t ) β t \beta_t β t β ~ t \tilde{\beta}_t β ~ t
Σ θ ( x t , t ) = exp ( v ⊙ log β t + ( 1 − v ) ⊙ log β ~ t ) \boldsymbol{\Sigma}_\theta(\mathbf{x}_t,t) = \exp\left(\mathbf{v} \odot \log \beta_t + (1-\mathbf{v}) \odot \log \tilde{\beta}_t\right) Σ θ ( x t , t ) = exp ( v ⊙ log β t + ( 1 − v ) ⊙ log β ~ t ) 其中 v \mathbf{v} v x \mathbf{x} x [ 0 , 1 ] [0, 1] [ 0 , 1 ]
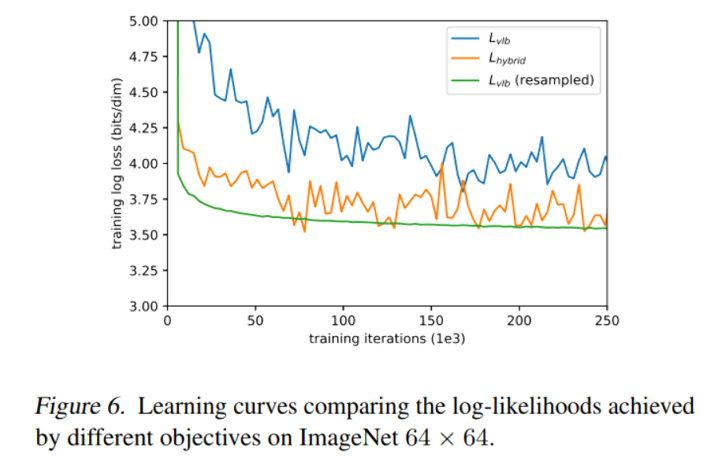
混合损失函数优化协方差 ¶ DDPM 原有的简化损失函数 L simple L_{\text{simple}} L simple μ θ \boldsymbol{\mu}_\theta μ θ ϵ θ \boldsymbol{\epsilon}_\theta ϵ θ Σ θ \boldsymbol{\Sigma}_\theta Σ θ
L hybrid = L simple + λ L vlb L_{\text{hybrid}} = L_{\text{simple}} + \lambda L_{\text{vlb}} L hybrid = L simple + λ L vlb 其中 λ = 0.001 \lambda=0.001 λ = 0.001 L simple L_{\text{simple}} L simple L vlb L_{\text{vlb}} L vlb
重要性采样与动态权重调整 ¶ 由于 L vlb L_{\text{vlb}} L vlb t t t t t t 重要性采样 (Importance Sampling)来优化 L vlb L_{\text{vlb}} L vlb
L vlb = E t ∼ p t [ L t p t ] , where p t ∝ E [ L t 2 ] and ∑ p t = 1 L_{\text{vlb}} = \mathbb{E}_{t \sim p_t}\left[\frac{L_t}{p_t}\right], \quad \text{where } p_t \propto \sqrt{\mathbb{E}\left[L_t^2\right]} \quad \text{and} \quad \sum p_t = 1 L vlb = E t ∼ p t [ p t L t ] , where p t ∝ E [ L t 2 ] and ∑ p t = 1 由于 E [ L t 2 ] \mathbb{E}[L_t^2] E [ L t 2 ] L t L_t L t p t p_t p t
U-Net架构与成熟模块组合 ¶ 扩散模型通常使用U-Net作为噪声预测模型 – 与已经成熟的模型组合:
增加模型深度与宽度(不是两者):两者都有帮助,但增加宽度在计
算上更高效,同时提供与增加深度类似的增益
增加注意力头的数量并将其应用于多种分辨率
借用 BigGAN 残差块进行上采样和下采样
自适应组标准化 —— 希望在训练/逆向过程中更好地结合时间步长(以及隐类别)信息
分类器引导的扩散模型 ¶ 条件生成对抗网络可以按照类标签为条件来合成特定类型的图像。我们可以将同样的想法应用于扩散模型。Nichol & Dhariwal (2021) 在噪声图像 x t − 1 \mathbf{x}_{t-1} x t − 1 p ϕ ( y ∣ x t − 1 , t − 1 ) p_\phi(y|\mathbf{x}_{t-1}, t-1) p ϕ ( y ∣ x t − 1 , t − 1 ) ∇ x log p ϕ ( y ∣ x t − 1 ) \nabla_{\mathbf{x}} \log p_\phi(y|\mathbf{x}_{t-1}) ∇ x log p ϕ ( y ∣ x t − 1 ) y y y
对于无条件逆向噪声过程 p θ ( x t − 1 ∣ x t ) p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_t) p θ ( x t − 1 ∣ x t ) y y y
p θ , ϕ ( x t − 1 ∣ x t , y ) = Z ⋅ p θ ( x t − 1 ∣ x t ) ⋅ p ϕ ( y ∣ x t − 1 ) p_{\theta,\phi}(\mathbf{x}_{t-1}|\mathbf{x}_t, y) = Z \cdot p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_t) \cdot p_\phi(y|\mathbf{x}_{t-1}) p θ , ϕ ( x t − 1 ∣ x t , y ) = Z ⋅ p θ ( x t − 1 ∣ x t ) ⋅ p ϕ ( y ∣ x t − 1 ) 其中 Z Z Z
分类器引导的核心思想:
分类器引导的数学推导 ¶ 逆向过程的条件分布为:
p θ ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ θ ( x t , t ) , Σ θ ( x t , t ) ) p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_t) = \mathcal{N}(\mathbf{x}_{t-1}; \boldsymbol{\mu}_\theta(\mathbf{x}_t, t), \boldsymbol{\Sigma}_\theta(\mathbf{x}_t, t)) p θ ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ θ ( x t , t ) , Σ θ ( x t , t )) 随着扩散迭代数递增,虽然 p θ ( x t − 1 ∣ x t ) p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_t) p θ ( x t − 1 ∣ x t ) Σ θ − 1 \boldsymbol{\Sigma}_\theta^{-1} Σ θ − 1 log p ϕ ( y ∣ x t − 1 ) \log p_\phi(y|\mathbf{x}_{t-1}) log p ϕ ( y ∣ x t − 1 ) x t − 1 = μ \mathbf{x}_{t-1} = \boldsymbol{\mu} x t − 1 = μ
log p ϕ ( y ∣ x t − 1 ) ≈ log p ϕ ( y ∣ x t − 1 ) ∣ x t − 1 = μ + ( x t − 1 − μ ) ⊤ ∇ x t − 1 log p ϕ ( y ∣ x t − 1 ) ∣ x t − 1 = μ \log p_\phi(y|\mathbf{x}_{t-1}) \approx \log p_\phi(y|\mathbf{x}_{t-1})\big|_{\mathbf{x}_{t-1}=\boldsymbol{\mu}} + (\mathbf{x}_{t-1} - \boldsymbol{\mu})^\top \nabla_{\mathbf{x}_{t-1}} \log p_\phi(y|\mathbf{x}_{t-1})\big|_{\mathbf{x}_{t-1}=\boldsymbol{\mu}} log p ϕ ( y ∣ x t − 1 ) ≈ log p ϕ ( y ∣ x t − 1 ) ∣ ∣ x t − 1 = μ + ( x t − 1 − μ ) ⊤ ∇ x t − 1 log p ϕ ( y ∣ x t − 1 ) ∣ ∣ x t − 1 = μ 将联合分布取对数:
log ( p θ ( x t − 1 ∣ x t ) ⋅ p ϕ ( y ∣ x t − 1 ) ) ≈ log N ( x t − 1 ; μ θ , Σ θ ) + log p ϕ ( y ∣ μ ) + ( x t − 1 − μ ) ⊤ g = − 1 2 ( x t − 1 − μ θ ) ⊤ Σ θ − 1 ( x t − 1 − μ θ ) + ( x t − 1 − μ ) ⊤ g + C \begin{aligned}
&\log\left(p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_t) \cdot p_\phi(y|\mathbf{x}_{t-1})\right) \\
&\approx \log \mathcal{N}(\mathbf{x}_{t-1}; \boldsymbol{\mu}_\theta, \boldsymbol{\Sigma}_\theta) + \log p_\phi(y|\boldsymbol{\mu}) + (\mathbf{x}_{t-1} - \boldsymbol{\mu})^\top \mathbf{g} \\
&= -\frac{1}{2}(\mathbf{x}_{t-1} - \boldsymbol{\mu}_\theta)^\top \boldsymbol{\Sigma}_\theta^{-1} (\mathbf{x}_{t-1} - \boldsymbol{\mu}_\theta) + (\mathbf{x}_{t-1} - \boldsymbol{\mu})^\top \mathbf{g} + C
\end{aligned} log ( p θ ( x t − 1 ∣ x t ) ⋅ p ϕ ( y ∣ x t − 1 ) ) ≈ log N ( x t − 1 ; μ θ , Σ θ ) + log p ϕ ( y ∣ μ ) + ( x t − 1 − μ ) ⊤ g = − 2 1 ( x t − 1 − μ θ ) ⊤ Σ θ − 1 ( x t − 1 − μ θ ) + ( x t − 1 − μ ) ⊤ g + C 其中 g = ∇ x t − 1 log p ϕ ( y ∣ x t − 1 ) ∣ x t − 1 = μ \mathbf{g} = \nabla_{\mathbf{x}_{t-1}} \log p_\phi(y|\mathbf{x}_{t-1})\big|_{\mathbf{x}_{t-1}=\boldsymbol{\mu}} g = ∇ x t − 1 log p ϕ ( y ∣ x t − 1 ) ∣ ∣ x t − 1 = μ
令 X = x t − 1 − μ θ \mathbf{X} = \mathbf{x}_{t-1} - \boldsymbol{\mu}_\theta X = x t − 1 − μ θ Σ = Σ θ \boldsymbol{\Sigma} = \boldsymbol{\Sigma}_\theta Σ = Σ θ
− 1 2 X ⊤ Σ − 1 X + X ⊤ g + C = − 1 2 X ⊤ Σ − 1 X + X ⊤ Σ − 1 Σ g + C = − 1 2 ( X − Σ g ) ⊤ Σ − 1 ( X − Σ g ) + C ′ = − 1 2 ( x t − 1 − ( μ θ + Σ g ) ) ⊤ Σ − 1 ( x t − 1 − ( μ θ + Σ g ) ) + C ′ \begin{aligned}
&-\frac{1}{2}\mathbf{X}^\top \boldsymbol{\Sigma}^{-1} \mathbf{X} + \mathbf{X}^\top \mathbf{g} + C \\
&= -\frac{1}{2}\mathbf{X}^\top \boldsymbol{\Sigma}^{-1} \mathbf{X} + \mathbf{X}^\top \boldsymbol{\Sigma}^{-1} \boldsymbol{\Sigma} \mathbf{g} + C \\
&= -\frac{1}{2}(\mathbf{X} - \boldsymbol{\Sigma}\mathbf{g})^\top \boldsymbol{\Sigma}^{-1} (\mathbf{X} - \boldsymbol{\Sigma}\mathbf{g}) + C' \\
&= -\frac{1}{2}(\mathbf{x}_{t-1} - (\boldsymbol{\mu}_\theta + \boldsymbol{\Sigma}\mathbf{g}))^\top \boldsymbol{\Sigma}^{-1} (\mathbf{x}_{t-1} - (\boldsymbol{\mu}_\theta + \boldsymbol{\Sigma}\mathbf{g})) + C'
\end{aligned} − 2 1 X ⊤ Σ − 1 X + X ⊤ g + C = − 2 1 X ⊤ Σ − 1 X + X ⊤ Σ − 1 Σ g + C = − 2 1 ( X − Σ g ) ⊤ Σ − 1 ( X − Σ g ) + C ′ = − 2 1 ( x t − 1 − ( μ θ + Σ g ) ) ⊤ Σ − 1 ( x t − 1 − ( μ θ + Σ g )) + C ′ 因此,条件分布仍然是高斯分布,均值发生了偏移:
p θ , ϕ ( x t − 1 ∣ x t , y ) = N ( x t − 1 ; μ θ + Σ θ ∇ x t − 1 log p ϕ ( y ∣ x t − 1 ) , Σ θ ) p_{\theta,\phi}(\mathbf{x}_{t-1}|\mathbf{x}_t, y) = \mathcal{N}\left(\mathbf{x}_{t-1}; \boldsymbol{\mu}_\theta + \boldsymbol{\Sigma}_\theta \nabla_{\mathbf{x}_{t-1}} \log p_\phi(y|\mathbf{x}_{t-1}), \boldsymbol{\Sigma}_\theta\right) p θ , ϕ ( x t − 1 ∣ x t , y ) = N ( x t − 1 ; μ θ + Σ θ ∇ x t − 1 log p ϕ ( y ∣ x t − 1 ) , Σ θ ) 添加梯度缩放变量 s s s
p θ , ϕ ( x t − 1 ∣ x t , y ) = N ( x t − 1 ; μ θ + s Σ θ ∇ x t − 1 log p ϕ ( y ∣ x t − 1 ) , Σ θ ) p_{\theta,\phi}(\mathbf{x}_{t-1}|\mathbf{x}_t, y) = \mathcal{N}\left(\mathbf{x}_{t-1}; \boldsymbol{\mu}_\theta + s \boldsymbol{\Sigma}_\theta \nabla_{\mathbf{x}_{t-1}} \log p_\phi(y|\mathbf{x}_{t-1}), \boldsymbol{\Sigma}_\theta\right) p θ , ϕ ( x t − 1 ∣ x t , y ) = N ( x t − 1 ; μ θ + s Σ θ ∇ x t − 1 log p ϕ ( y ∣ x t − 1 ) , Σ θ ) Algorithm 1: Classifier Guided Diffusion Sampling
Input: given a diffusion model ( μ θ ( x t ) , Σ θ ( x t ) ) , classifier p ϕ ( y ∣ x t ) , and gradient scale s . x T ∼ N ( 0 , I ) for t = T , … , 1 do μ , Σ ← μ θ ( x t , t ) , Σ θ ( x t , t ) x t − 1 ∼ N ( μ + s Σ ∇ x t log p ϕ ( y ∣ x t ) , Σ ) end for return x 0 \begin{array}{l}
\hline
\textbf{Input: } \text{ given a diffusion model }\left(\mu_\theta\left(x_t\right), \Sigma_\theta\left(x_t\right)\right) \text {, classifier } p_\phi\left(y \mid x_t\right) \text {, and gradient scale } s \text {. }\\
\hline
\mathbf{x}_T \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) \\
\textbf{for } t = T, \ldots, 1 \textbf{ do} \\
\quad \boldsymbol{\mu}, \boldsymbol{\Sigma} \leftarrow \boldsymbol{\mu}_\theta(\mathbf{x}_t, t), \boldsymbol{\Sigma}_\theta(\mathbf{x}_t, t) \\
\quad \mathbf{x}_{t-1} \sim \mathcal{N}\left(\boldsymbol{\mu} + s \boldsymbol{\Sigma} \nabla_{\mathbf{x}_t} \log p_\phi(y|\mathbf{x}_t), \boldsymbol{\Sigma}\right) \\
\textbf{end for} \\
\textbf{return } \mathbf{x}_0 \\
\hline
\end{array} Input: given a diffusion model ( μ θ ( x t ) , Σ θ ( x t ) ) , classifier p ϕ ( y ∣ x t ) , and gradient scale s . x T ∼ N ( 0 , I ) for t = T , … , 1 do μ , Σ ← μ θ ( x t , t ) , Σ θ ( x t , t ) x t − 1 ∼ N ( μ + s Σ ∇ x t log p ϕ ( y ∣ x t ) , Σ ) end for return x 0 基于 Score Matching 的分类器引导 ¶ 前面条件采样的推导仅适用于随机扩散采样过程,但不适用于确定性采样方法(如 DDIM)。下面介绍一种基于样本梯度匹配(Score Matching)的采样方法。
Score 是对数概率密度关于样本的梯度 s θ ( x t , t ) ≈ ∇ x t log p θ ( x t ) \mathbf{s}_\theta(\mathbf{x}_t, t) \approx \nabla_{\mathbf{x}_t} \log p_\theta(\mathbf{x}_t) s θ ( x t , t ) ≈ ∇ x t log p θ ( x t )
对于样本 x t \mathbf{x}_t x t
∇ x t log p θ ( x t ) ≈ − ϵ θ ( x t , t ) 1 − α ˉ t \nabla_{\mathbf{x}_t} \log p_\theta(\mathbf{x}_t) \approx -\frac{\boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t)}{\sqrt{1-\bar{\alpha}_t}} ∇ x t log p θ ( x t ) ≈ − 1 − α ˉ t ϵ θ ( x t , t ) 详细推导过程:
Step 1: 条件分布的 Score
根据前向扩散过程的重参数化,我们有:
q ( x t ∣ x 0 ) = N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) q(\mathbf{x}_t|\mathbf{x}_0) = \mathcal{N}(\mathbf{x}_t; \sqrt{\bar{\alpha}_t}\mathbf{x}_0, (1-\bar{\alpha}_t)\mathbf{I}) q ( x t ∣ x 0 ) = N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) 这意味着 x t \mathbf{x}_t x t
x t = α ˉ t x 0 + 1 − α ˉ t ϵ , where ϵ ∼ N ( 0 , I ) \mathbf{x}_t = \sqrt{\bar{\alpha}_t}\mathbf{x}_0 + \sqrt{1-\bar{\alpha}_t}\boldsymbol{\epsilon}, \quad \text{where } \boldsymbol{\epsilon} \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) x t = α ˉ t x 0 + 1 − α ˉ t ϵ , where ϵ ∼ N ( 0 , I ) Step 2: 高斯分布的 Score 公式
对于一般的高斯分布 x ∼ N ( μ , σ 2 I ) \mathbf{x} \sim \mathcal{N}(\boldsymbol{\mu}, \sigma^2\mathbf{I}) x ∼ N ( μ , σ 2 I )
p ( x ) = 1 ( 2 π σ 2 ) d / 2 exp ( − ∥ x − μ ∥ 2 2 σ 2 ) p(\mathbf{x}) = \frac{1}{(2\pi\sigma^2)^{d/2}} \exp\left(-\frac{\|\mathbf{x} - \boldsymbol{\mu}\|^2}{2\sigma^2}\right) p ( x ) = ( 2 π σ 2 ) d /2 1 exp ( − 2 σ 2 ∥ x − μ ∥ 2 ) 取对数并对 x \mathbf{x} x
∇ x log p ( x ) = − x − μ σ 2 \nabla_{\mathbf{x}} \log p(\mathbf{x}) = -\frac{\mathbf{x} - \boldsymbol{\mu}}{\sigma^2} ∇ x log p ( x ) = − σ 2 x − μ 由于 x = μ + σ ϵ \mathbf{x} = \boldsymbol{\mu} + \sigma\boldsymbol{\epsilon} x = μ + σ ϵ ϵ ∼ N ( 0 , I ) \boldsymbol{\epsilon} \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) ϵ ∼ N ( 0 , I )
∇ x log p ( x ) = − σ ϵ σ 2 = − ϵ σ \nabla_{\mathbf{x}} \log p(\mathbf{x}) = -\frac{\sigma\boldsymbol{\epsilon}}{\sigma^2} = -\frac{\boldsymbol{\epsilon}}{\sigma} ∇ x log p ( x ) = − σ 2 σ ϵ = − σ ϵ Step 3: 条件分布的 Score
将此结果应用于扩散模型。对于 q ( x t ∣ x 0 ) q(\mathbf{x}_t|\mathbf{x}_0) q ( x t ∣ x 0 ) μ = α ˉ t x 0 \boldsymbol{\mu} = \sqrt{\bar{\alpha}_t}\mathbf{x}_0 μ = α ˉ t x 0 σ = 1 − α ˉ t \sigma = \sqrt{1-\bar{\alpha}_t} σ = 1 − α ˉ t
∇ x t log q ( x t ∣ x 0 ) = − ϵ 1 − α ˉ t \nabla_{\mathbf{x}_t} \log q(\mathbf{x}_t|\mathbf{x}_0) = -\frac{\boldsymbol{\epsilon}}{\sqrt{1-\bar{\alpha}_t}} ∇ x t log q ( x t ∣ x 0 ) = − 1 − α ˉ t ϵ Step 4: 从条件 Score 到边缘 Score(关键步骤)
我们想要的是边缘分布 q ( x t ) q(\mathbf{x}_t) q ( x t )
q ( x t ) = ∫ q ( x t ∣ x 0 ) q ( x 0 ) d x 0 q(\mathbf{x}_t) = \int q(\mathbf{x}_t|\mathbf{x}_0) q(\mathbf{x}_0) d\mathbf{x}_0 q ( x t ) = ∫ q ( x t ∣ x 0 ) q ( x 0 ) d x 0 对其求 Score:
∇ x t log q ( x t ) = ∇ x t q ( x t ) q ( x t ) = ∫ ∇ x t q ( x t ∣ x 0 ) q ( x 0 ) d x 0 q ( x t ) = ∫ q ( x t ∣ x 0 ) q ( x 0 ) q ( x t ) ⋅ ∇ x t log q ( x t ∣ x 0 ) d x 0 = ∫ q ( x 0 ∣ x t ) ⋅ ∇ x t log q ( x t ∣ x 0 ) d x 0 = E q ( x 0 ∣ x t ) [ ∇ x t log q ( x t ∣ x 0 ) ] \begin{aligned}
\nabla_{\mathbf{x}_t} \log q(\mathbf{x}_t) &= \frac{\nabla_{\mathbf{x}_t} q(\mathbf{x}_t)}{q(\mathbf{x}_t)} = \frac{\int \nabla_{\mathbf{x}_t} q(\mathbf{x}_t|\mathbf{x}_0) q(\mathbf{x}_0) d\mathbf{x}_0}{q(\mathbf{x}_t)} \\
&= \int \frac{q(\mathbf{x}_t|\mathbf{x}_0) q(\mathbf{x}_0)}{q(\mathbf{x}_t)} \cdot \nabla_{\mathbf{x}_t} \log q(\mathbf{x}_t|\mathbf{x}_0) d\mathbf{x}_0 \\
&= \int q(\mathbf{x}_0|\mathbf{x}_t) \cdot \nabla_{\mathbf{x}_t} \log q(\mathbf{x}_t|\mathbf{x}_0) d\mathbf{x}_0 \\
&= \mathbb{E}_{q(\mathbf{x}_0|\mathbf{x}_t)}\left[\nabla_{\mathbf{x}_t} \log q(\mathbf{x}_t|\mathbf{x}_0)\right]
\end{aligned} ∇ x t log q ( x t ) = q ( x t ) ∇ x t q ( x t ) = q ( x t ) ∫ ∇ x t q ( x t ∣ x 0 ) q ( x 0 ) d x 0 = ∫ q ( x t ) q ( x t ∣ x 0 ) q ( x 0 ) ⋅ ∇ x t log q ( x t ∣ x 0 ) d x 0 = ∫ q ( x 0 ∣ x t ) ⋅ ∇ x t log q ( x t ∣ x 0 ) d x 0 = E q ( x 0 ∣ x t ) [ ∇ x t log q ( x t ∣ x 0 ) ] 代入条件 Score:
∇ x t log q ( x t ) = E q ( x 0 ∣ x t ) [ − ϵ 1 − α ˉ t ] = − E q ( x 0 ∣ x t ) [ ϵ ] 1 − α ˉ t \nabla_{\mathbf{x}_t} \log q(\mathbf{x}_t) = \mathbb{E}_{q(\mathbf{x}_0|\mathbf{x}_t)}\left[-\frac{\boldsymbol{\epsilon}}{\sqrt{1-\bar{\alpha}_t}}\right] = -\frac{\mathbb{E}_{q(\mathbf{x}_0|\mathbf{x}_t)}[\boldsymbol{\epsilon}]}{\sqrt{1-\bar{\alpha}_t}} ∇ x t log q ( x t ) = E q ( x 0 ∣ x t ) [ − 1 − α ˉ t ϵ ] = − 1 − α ˉ t E q ( x 0 ∣ x t ) [ ϵ ] Step 5: 神经网络如何学习这个期望
在训练噪声预测网络 ϵ θ ( x t , t ) \boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t) ϵ θ ( x t , t )
L = E q ( x 0 ) , ϵ [ ∥ ϵ − ϵ θ ( x t , t ) ∥ 2 ] L = \mathbb{E}_{q(\mathbf{x}_0), \boldsymbol{\epsilon}}\left[\|\boldsymbol{\epsilon} - \boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t)\|^2\right] L = E q ( x 0 ) , ϵ [ ∥ ϵ − ϵ θ ( x t , t ) ∥ 2 ] 最小化均方误差的最优解恰好是条件期望 :
ϵ θ ∗ ( x t , t ) = E q ( x 0 ∣ x t ) [ ϵ ] \boldsymbol{\epsilon}_\theta^*(\mathbf{x}_t, t) = \mathbb{E}_{q(\mathbf{x}_0|\mathbf{x}_t)}[\boldsymbol{\epsilon}] ϵ θ ∗ ( x t , t ) = E q ( x 0 ∣ x t ) [ ϵ ] 因此,训练好的神经网络隐式地学习了 E q ( x 0 ∣ x t ) [ ϵ ] \mathbb{E}_{q(\mathbf{x}_0|\mathbf{x}_t)}[\boldsymbol{\epsilon}] E q ( x 0 ∣ x t ) [ ϵ ]
∇ x t log q ( x t ) ≈ ∇ x t log p θ ( x t ) ≈ − ϵ θ ( x t , t ) 1 − α ˉ t \nabla_{\mathbf{x}_t} \log q(\mathbf{x}_t) \approx \nabla_{\mathbf{x}_t} \log p_\theta(\mathbf{x}_t) \approx -\frac{\boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t)}{\sqrt{1-\bar{\alpha}_t}} ∇ x t log q ( x t ) ≈ ∇ x t log p θ ( x t ) ≈ − 1 − α ˉ t ϵ θ ( x t , t ) 这就建立了 Score 函数 与噪声预测网络 之间的关系。
对于样本 x t \mathbf{x}_t x t y y y
∇ x t log ( p θ ( x t ) p ϕ ( y ∣ x t ) ) = ∇ x t log p θ ( x t ) + ∇ x t log p ϕ ( y ∣ x t ) ≈ − ϵ θ ( x t , t ) 1 − α ˉ t + ∇ x t log p ϕ ( y ∣ x t ) = − 1 1 − α ˉ t ( ϵ θ ( x t , t ) − 1 − α ˉ t ∇ x t log p ϕ ( y ∣ x t ) ) \begin{aligned}
\nabla_{\mathbf{x}_t} \log\left(p_\theta(\mathbf{x}_t) p_\phi(y|\mathbf{x}_t)\right) &= \nabla_{\mathbf{x}_t} \log p_\theta(\mathbf{x}_t) + \nabla_{\mathbf{x}_t} \log p_\phi(y|\mathbf{x}_t) \\
&\approx -\frac{\boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t)}{\sqrt{1-\bar{\alpha}_t}} + \nabla_{\mathbf{x}_t} \log p_\phi(y|\mathbf{x}_t) \\
&= -\frac{1}{\sqrt{1-\bar{\alpha}_t}}\left(\boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t) - \sqrt{1-\bar{\alpha}_t} \nabla_{\mathbf{x}_t} \log p_\phi(y|\mathbf{x}_t)\right)
\end{aligned} ∇ x t log ( p θ ( x t ) p ϕ ( y ∣ x t ) ) = ∇ x t log p θ ( x t ) + ∇ x t log p ϕ ( y ∣ x t ) ≈ − 1 − α ˉ t ϵ θ ( x t , t ) + ∇ x t log p ϕ ( y ∣ x t ) = − 1 − α ˉ t 1 ( ϵ θ ( x t , t ) − 1 − α ˉ t ∇ x t log p ϕ ( y ∣ x t ) ) 因此,新的分类引导噪声预测器为:
ϵ ˉ θ ( x t , t ) = ϵ θ ( x t , t ) − 1 − α ˉ t ∇ x t log p ϕ ( y ∣ x t ) \bar{\boldsymbol{\epsilon}}_\theta(\mathbf{x}_t, t) = \boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t) - \sqrt{1-\bar{\alpha}_t} \nabla_{\mathbf{x}_t} \log p_\phi(y|\mathbf{x}_t) ϵ ˉ θ ( x t , t ) = ϵ θ ( x t , t ) − 1 − α ˉ t ∇ x t log p ϕ ( y ∣ x t ) 为了控制分类器引导的强度,添加一个权重 s s s
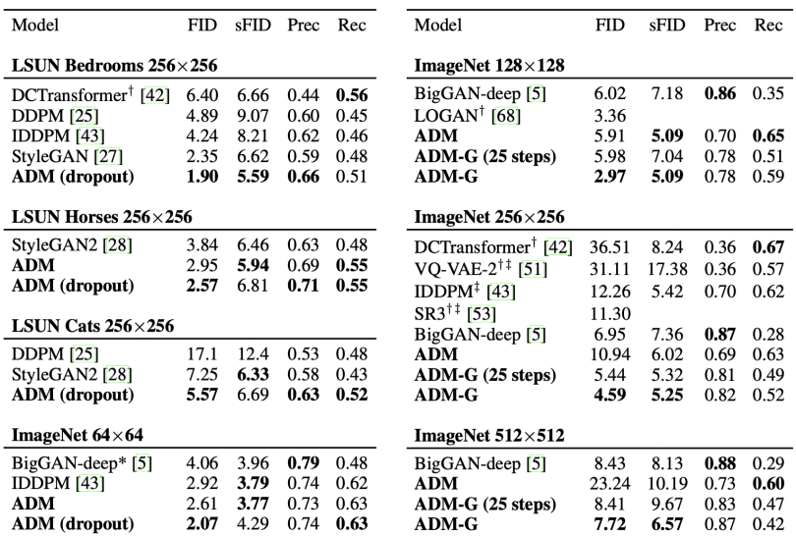
ϵ ˉ θ ( x t , t ) = ϵ θ ( x t , t ) − s 1 − α ˉ t ∇ x t log p ϕ ( y ∣ x t ) \bar{\boldsymbol{\epsilon}}_\theta(\mathbf{x}_t, t) = \boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t) - s\sqrt{1-\bar{\alpha}_t} \nabla_{\mathbf{x}_t} \log p_\phi(y|\mathbf{x}_t) ϵ ˉ θ ( x t , t ) = ϵ θ ( x t , t ) − s 1 − α ˉ t ∇ x t log p ϕ ( y ∣ x t ) 由此产生的消融扩散模型 (Ablated Diffusion Model, ADM) 和带有附加分类器引导的模型 (ADM-G) 能够取得比 2022 年最好的 BigGAN 网络模型更好的结果。
Algorithm 2: Classifier Guided DDIM Sampling
Input: given a diffusion model ϵ θ ( x t ) , classifier p ϕ ( y ∣ x t ) , and gradient scale s . x T ∼ N ( 0 , I ) for t = T , … , 1 do ϵ ^ ← ϵ θ ( x t ) − s 1 − α ˉ t ∇ x t log p ϕ ( y ∣ x t ) x t − 1 ← α ˉ t − 1 ( x t − 1 − α ˉ t ϵ ^ α ˉ t ) + 1 − α ˉ t − 1 ϵ ^ end for return x 0 \begin{array}{l}
\hline
\textbf{Input: } \text{given a diffusion model} \epsilon_\theta\left(x_t\right), \text{classifier} p_\phi\left(y \mid x_t\right), \text{and gradient scale} s. \\
\hline
\mathbf{x}_T \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) \\
\textbf{for } t = T, \ldots, 1 \textbf{ do} \\
\quad \hat{\boldsymbol{\epsilon}} \leftarrow \boldsymbol{\epsilon}_\theta(\mathbf{x}_t) - s\sqrt{1-\bar{\alpha}_t} \nabla_{\mathbf{x}_t} \log p_\phi(y|\mathbf{x}_t) \\
\quad \mathbf{x}_{t-1} \leftarrow \sqrt{\bar{\alpha}_{t-1}}\left(\frac{\mathbf{x}_t - \sqrt{1-\bar{\alpha}_t}\hat{\boldsymbol{\epsilon}}}{\sqrt{\bar{\alpha}_t}}\right) + \sqrt{1-\bar{\alpha}_{t-1}}\hat{\boldsymbol{\epsilon}} \\
\textbf{end for} \\
\textbf{return } \mathbf{x}_0 \\
\hline
\end{array} Input: given a diffusion model ϵ θ ( x t ) , classifier p ϕ ( y ∣ x t ) , and gradient scale s . x T ∼ N ( 0 , I ) for t = T , … , 1 do ϵ ^ ← ϵ θ ( x t ) − s 1 − α ˉ t ∇ x t log p ϕ ( y ∣ x t ) x t − 1 ← α ˉ t − 1 ( α ˉ t x t − 1 − α ˉ t ϵ ^ ) + 1 − α ˉ t − 1 ϵ ^ end for return x 0 评估指标 ¶ 高层次上:
扩散模型击败GAN:样本质量对比 ¶ 扩散模型与GAN的视觉效果对比 ¶ 无分类器引导的动机与原理 ¶ 分类器引导(Classifier Guidance)效果很好,但是有以下问题:
无法直接使用预训练的分类器,因为分类器必须针对带噪声的样本进行专门训练;
分类器引导将分类器的梯度注入到扩散模型训练过程,这导致模型是否真正学会了鲁棒性,还是仅仅像对抗攻击一样被梯度牵引,变得难以解释;
为了避免这些困境,研究人员提出跳过外部分类器,同时联合训练条件和无条件扩散模型。
如果没有独立的分类器,我们仍然可以通过合并条件和无条件扩散模型的 score 梯度来进行引导。具体做法如下:
通过 score 估计器 ϵ θ ( x t , t ) \boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t) ϵ θ ( x t , t ) p θ ( x ) p_\theta(\mathbf{x}) p θ ( x ) p θ ( x ∣ y ) p_\theta(\mathbf{x}|y) p θ ( x ∣ y ) ( x , y ) (\mathbf{x}, y) ( x , y ) p θ ( x ∣ y ) p_\theta(\mathbf{x}|y) p θ ( x ∣ y ) y y y ϵ θ ( x t , t ) = ϵ θ ( x t , t , y = ∅ ) \boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t) = \boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t, y = \emptyset) ϵ θ ( x t , t ) = ϵ θ ( x t , t , y = ∅ )
隐式分类器的梯度 ∇ x t log p θ ( y ∣ x t ) \nabla_{\mathbf{x}_t} \log p_\theta(y|\mathbf{x}_t) ∇ x t log p θ ( y ∣ x t ) ∇ x t log p θ ( x t ∣ y ) \nabla_{\mathbf{x}_t} \log p_\theta(\mathbf{x}_t|y) ∇ x t log p θ ( x t ∣ y ) ∇ x t log p θ ( x t ) \nabla_{\mathbf{x}_t} \log p_\theta(\mathbf{x}_t) ∇ x t log p θ ( x t ) ϵ ^ θ ( x t , t , y ) \hat{\epsilon}_\theta(\mathbf{x}_t, t, y) ϵ ^ θ ( x t , t , y )
推导如下:
首先,利用贝叶斯公式的对数形式:
log p θ ( y ∣ x t ) = log p θ ( x t ∣ y ) + log p ( y ) − log p θ ( x t ) \log p_\theta(y|\mathbf{x}_t) = \log p_\theta(\mathbf{x}_t|y) + \log p(y) - \log p_\theta(\mathbf{x}_t) log p θ ( y ∣ x t ) = log p θ ( x t ∣ y ) + log p ( y ) − log p θ ( x t ) x t \mathbf{x}_t x t
∇ x t log p θ ( y ∣ x t ) = ∇ x t log p θ ( x t ∣ y ) − ∇ x t log p θ ( x t ) \nabla_{\mathbf{x}_t} \log p_\theta(y|\mathbf{x}_t) = \nabla_{\mathbf{x}_t} \log p_\theta(\mathbf{x}_t|y) - \nabla_{\mathbf{x}_t} \log p_\theta(\mathbf{x}_t) ∇ x t log p θ ( y ∣ x t ) = ∇ x t log p θ ( x t ∣ y ) − ∇ x t log p θ ( x t ) 而根据 score 匹配的定义,无条件 score 估计器可近似为:
∇ x t log p θ ( x t ) ≈ − ϵ θ ( x t , t ) 1 − α ˉ t \nabla_{\mathbf{x}_t}\log p_\theta(\mathbf{x}_t) \approx - \frac{\epsilon_\theta(\mathbf{x}_t, t)}{\sqrt{1-\bar{\alpha}_t}} ∇ x t log p θ ( x t ) ≈ − 1 − α ˉ t ϵ θ ( x t , t ) 同理,有条件 score 可近似为:
∇ x t log p θ ( x t ∣ y ) ≈ − ϵ θ ( x t , t , y ) 1 − α ˉ t \nabla_{\mathbf{x}_t}\log p_\theta(\mathbf{x}_t|y) \approx - \frac{\epsilon_\theta(\mathbf{x}_t, t, y)}{\sqrt{1-\bar{\alpha}_t}} ∇ x t log p θ ( x t ∣ y ) ≈ − 1 − α ˉ t ϵ θ ( x t , t , y ) 所以,
∇ x t log p θ ( y ∣ x t ) = ∇ x t log p θ ( x t ∣ y ) − ∇ x t log p θ ( x t ) = − 1 1 − α ˉ t [ ϵ θ ( x t , t , y ) − ϵ θ ( x t , t ) ] \nabla_{\mathbf{x}_t} \log p_\theta(y|\mathbf{x}_t)
= \nabla_{\mathbf{x}_t} \log p_\theta(\mathbf{x}_t|y) - \nabla_{\mathbf{x}_t} \log p_\theta(\mathbf{x}_t)
= -\frac{1}{\sqrt{1-\bar{\alpha}_t}}\left[\epsilon_\theta(\mathbf{x}_t, t, y) - \epsilon_\theta(\mathbf{x}_t, t)\right] ∇ x t log p θ ( y ∣ x t ) = ∇ x t log p θ ( x t ∣ y ) − ∇ x t log p θ ( x t ) = − 1 − α ˉ t 1 [ ϵ θ ( x t , t , y ) − ϵ θ ( x t , t ) ] 将上式代入到新的分类引导预测器中,有:
ϵ ^ θ ( x t , t , y ) = ϵ θ ( x t , t , y ) − 1 − α ˉ t s ∇ x t log p θ ( y ∣ x t ) \hat{\epsilon}_\theta(\mathbf{x}_t, t, y) = \epsilon_\theta(\mathbf{x}_t, t, y) - \sqrt{1-\bar{\alpha}_t} s \nabla_{\mathbf{x}_t} \log p_\theta(y|\mathbf{x}_t) ϵ ^ θ ( x t , t , y ) = ϵ θ ( x t , t , y ) − 1 − α ˉ t s ∇ x t log p θ ( y ∣ x t )
= ϵ θ ( x t , t , y ) + s ( ϵ θ ( x t , t , y ) − ϵ θ ( x t , t ) ) = \epsilon_\theta(\mathbf{x}_t, t, y) + s \left( \epsilon_\theta(\mathbf{x}_t, t, y) - \epsilon_\theta(\mathbf{x}_t, t) \right ) = ϵ θ ( x t , t , y ) + s ( ϵ θ ( x t , t , y ) − ϵ θ ( x t , t ) )
= ( s + 1 ) ϵ θ ( x t , t , y ) − s ϵ θ ( x t , t ) = (s+1)\, \epsilon_\theta(\mathbf{x}_t, t, y)\ -\ s\, \epsilon_\theta(\mathbf{x}_t, t) = ( s + 1 ) ϵ θ ( x t , t , y ) − s ϵ θ ( x t , t ) 无分类器引导的优缺点分析 ¶ 无分类器引导的实现非常简单,而分类器引导则需要在噪声样本上训练外部分类器
无分类器引导不采用任何类型的分类器梯度,不能被解释为对抗性攻击:它更符合 传统的生成模型
无分类器引导比分类器引导慢,因为需要两倍的逆向扩散步骤
两者都会降低样本多样性以提高样本保真度/质量
多样性(无引导样本,前两行)与保真度(有引导样本,后两行)
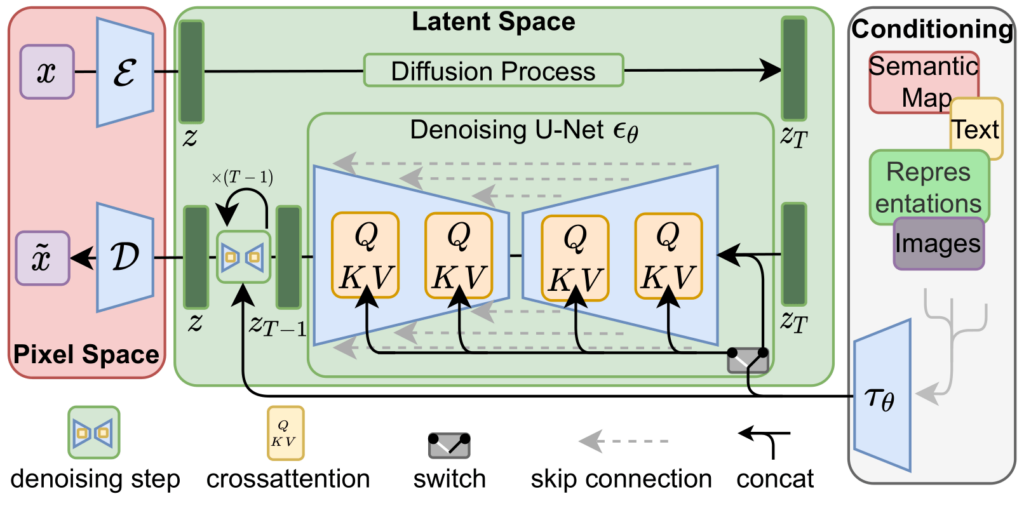
隐扩散模型 ¶ 隐扩散模型(Latent Diffusion Model,LDM;Rombach & Blattmann 等人,2022)在隐空间而非像素空间中运行扩散过程,这使得训练成本更低且推理速度更快。该方法的灵感来源于:图像中的大部分信息比特位用于表达感知细节,而在经过剧烈压缩后,其语义和概念结构依然能够得以保持。LDM通过生成式建模学习,大致上将感知压缩和语义压缩分开处理:首先利用自编码器去除像素级冗余,然后在习得的隐空间中通过扩散过程来操作/生成语义概念,从而实现这一目标。
感知压缩过程依赖于一个自编码器模型。该模型使用一个编码器 E \mathcal{E} E x x x z = E ( x ) z=\mathcal{E}(x) z = E ( x ) D \mathcal{D} D x ~ = D ( z ) \widetilde{x}=\mathcal{D}(z) x = D ( z )
隐扩散模型分为两个阶段:
训练感知压缩模型,去除不相关的高级细节并学习语义上与高级图像像素空间等效的隐空间。
损失是重建损失、促进高质量解码器重建的对抗性损失(还记得 GAN 吗?)和正则化项的组合:
L A u t o e n c o d e r = min E , D max ψ ( L r e c ( x , D ( E ( x ) ) ) − L a d v ( D ( E ( x ) ) ) + log D ψ ( x ) + L r e g ( x ; E , D ) ) L_{\mathrm{Autoencoder}} =
\min_{\mathcal{E},\mathcal{D}} \max_{\psi}
\left(
L_{\mathrm{rec}}\left(x,\mathcal{D}\left(\mathcal{E}\left(x\right)\right)\right)
- L_{\mathrm{adv}}\left(\mathcal{D}\left(\mathcal{E}\left(x\right)\right)\right)
+ \log D_\psi\left(x\right)
+ L_{\mathrm{reg}}\left(x;\mathcal{E},\mathcal{D}\right)
\right) L Autoencoder = E , D min ψ max ( L rec ( x , D ( E ( x ) ) ) − L adv ( D ( E ( x ) ) ) + log D ψ ( x ) + L reg ( x ; E , D ) ) 在自编码器训练过程中,LDM 探索了两种正则化方法,以避免隐空间中出现任意高的方差。
交叉注意力机制的条件生成 ¶ 扩散和去噪过程发生在隐向量 z z z
每种类型的条件信息都与一个领域特定的编码器 τ θ \tau_\theta τ θ y y y τ θ ( y ) \tau_\theta(y) τ θ ( y )
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K ⊤ d ) ⋅ V \mathrm{Attention}(\mathbf{Q}, \mathbf{K}, \mathbf{V}) = \mathrm{softmax}\left(\frac{\mathbf{Q}\mathbf{K}^\top}{\sqrt{d}}\right)\cdot \mathbf{V} Attention ( Q , K , V ) = softmax ( d Q K ⊤ ) ⋅ V 其中:Q = W Q ( i ) ⋅ φ i ( z i ) \mathbf{Q} = \mathbf{W}_Q^{(i)}\cdot\varphi_i(\mathbf{z}_i) Q = W Q ( i ) ⋅ φ i ( z i ) K = W K ( i ) ⋅ τ θ ( y ) \mathbf{K} = \mathbf{W}_K^{(i)} \cdot \tau_\theta(y) K = W K ( i ) ⋅ τ θ ( y ) V = W V ( i ) ⋅ τ θ ( y ) \mathbf{V} = \mathbf{W}_V^{(i)} \cdot \tau_\theta(y) V = W V ( i ) ⋅ τ θ ( y )
在这个隐空间中进行扩散过程。这样做有几个好处:
扩散过程仅关注样本的相关语义位
在低维空间中执行扩散效率明显更高
from typing import Dict, Tuple
import torch
import torch.nn as nn
class DDPM(nn.Module):
"""
去噪扩散概率模型 (Denoising Diffusion Probabilistic Model)
register_buffer 允许我们通过名称自由访问这些张量。它有助于设备放置。
"""
def __init__(self, eps_model: nn.Module, betas: Tuple[float, float], n_T: int, criterion: nn.Module = nn.MSELoss()) -> None:
super(DDPM, self).__init__()
self.eps_model = eps_model
# register_buffer 允许我们通过名称自由访问这些张量。它有助于设备放置。
for k, v in ddpm_schedules(betas[0], betas[1], n_T).items():
self.register_buffer(k, v)
self.n_T = n_T
self.criterion = criterion
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""进行正向扩散x_t,并尝试使用eps_model从x_t预测epsilon值。这实现了论文中的算法1。"""
# t ~ Uniform(0, n_T)
_ts = torch.randint(1, self.n_T + 1, (x.shape[0],)).to(x.device)
eps = torch.randn_like(x) # eps ~ N(0, 1)
x_t = (self.sqrtab[_ts, None, None, None] * x
+ self.sqrtmab[_ts, None, None, None] * eps)
# 运用噪声模型预测噪声,计算损失
return self.criterion(eps, self.eps_model(x_t, _ts / self.n_T))
def sample(self, n_sample: int, size, device) -> torch.Tensor:
x_i = torch.randn(n_sample, *size).to(device) # x_T ~ N(0, 1)
# 根据算法2进行采样,逻辑完全相同。
for i in range(self.n_T, 0, -1):
z = torch.randn(n_sample, *size).to(device) if i > 1 else 0
eps = self.eps_model(x_i, torch.tensor(i / self.n_T).to(device).repeat(n_sample, 1))
x_i = (self.oneover_sqrta[i] * (x_i - eps * self.mab_over_sqrtmab[i])
+ self.sqrt_beta_t[i] * z)
return x_i
DDPM 训练算法 ¶ Algorithm 1: Training repeat x 0 ∼ q ( x 0 ) 从数据分布中采样 t ∼ Uniform ( { 1 , … , T } ) 随机选择时间步 ϵ ∼ N ( 0 , I ) 采样高斯噪声 梯度下降更新: ∇ θ ∥ ϵ − ϵ θ ( α ˉ t x 0 + 1 − α ˉ t ϵ , t ) ∥ 2 until converged \begin{array}{l}
\textbf{Algorithm 1: Training} \\
\hline
\textbf{repeat} \\
\quad \mathbf{x}_0 \sim q(\mathbf{x}_0) \quad \text{从数据分布中采样} \\
\quad t \sim \text{Uniform}(\{1, \ldots, T\}) \quad \text{随机选择时间步} \\
\quad \boldsymbol{\epsilon} \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) \quad \text{采样高斯噪声} \\
\quad \text{梯度下降更新: } \nabla_\theta \left\|\boldsymbol{\epsilon} - \boldsymbol{\epsilon}_\theta\left(\sqrt{\bar{\alpha}_t}\mathbf{x}_0 + \sqrt{1-\bar{\alpha}_t}\boldsymbol{\epsilon}, t\right)\right\|^2 \\
\textbf{until converged}
\end{array} Algorithm 1: Training repeat x 0 ∼ q ( x 0 ) 从数据分布中采样 t ∼ Uniform ({ 1 , … , T }) 随机选择时间步 ϵ ∼ N ( 0 , I ) 采样高斯噪声 梯度下降更新 : ∇ θ ∥ ∥ ϵ − ϵ θ ( α ˉ t x 0 + 1 − α ˉ t ϵ , t ) ∥ ∥ 2 until converged DDPM 采样算法(根据逆向分布采样公式) ¶ Algorithm 2: Sampling x T ∼ N ( 0 , I ) 从纯噪声开始 for t = T , … , 1 do z ∼ N ( 0 , I ) if t > 1 , else z = 0 x t − 1 = 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ θ ( x t , t ) ) + σ t z end for return x 0 \begin{array}{l}
\textbf{Algorithm 2: Sampling} \\
\hline
\mathbf{x}_T \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) \quad \text{从纯噪声开始} \\
\textbf{for } t = T, \ldots, 1 \textbf{ do} \\
\quad \mathbf{z} \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) \text{ if } t > 1 \text{, else } \mathbf{z} = \mathbf{0} \\
\quad \mathbf{x}_{t-1} = \frac{1}{\sqrt{\alpha_t}}\left(\mathbf{x}_t - \frac{1-\alpha_t}{\sqrt{1-\bar{\alpha}_t}}\boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t)\right) + \sigma_t\mathbf{z} \\
\textbf{end for} \\
\textbf{return } \mathbf{x}_0
\end{array} Algorithm 2: Sampling x T ∼ N ( 0 , I ) 从纯噪声开始 for t = T , … , 1 do z ∼ N ( 0 , I ) if t > 1 , else z = 0 x t − 1 = α t 1 ( x t − 1 − α ˉ t 1 − α t ϵ θ ( x t , t ) ) + σ t z end for return x 0 def ddpm_schedules(beta1: float, beta2: float, T: int) -> Dict[str, torch.Tensor]:
"""为DDPM采样、训练过程预先计算的调度变量"""
assert beta1 < beta2 < 1.0, "beta1 and beta2 must be in (0, 1)"
beta_t = (beta2 - beta1) * torch.arange(0, T + 1, dtype=torch.float32) / T + beta1
sqrt_beta_t = torch.sqrt(beta_t)
alpha_t = 1 - beta_t
log_alpha_t = torch.log(alpha_t)
alphabar_t = torch.cumsum(log_alpha_t, dim=0).exp()
sqrtab = torch.sqrt(alphabar_t)
oneover_sqrta = 1 / torch.sqrt(alpha_t)
sqrtmab = torch.sqrt(1 - alphabar_t)
mab_over_sqrtmab_inv = (1 - alpha_t) / sqrtmab
return {
"alpha_t": alpha_t,
"oneover_sqrta": oneover_sqrta, # 1/sqrt(alpha_t)
"sqrt_beta_t": sqrt_beta_t,
"alphabar_t": alphabar_t, # bar{alpha_t}
"sqrtab": sqrtab, # sqrt(bar{alpha_t})
"sqrtmab": sqrtmab, # sqrt(1-bar{alpha_t})
"mab_over_sqrtmab": mab_over_sqrtmab_inv, # (1-alpha_t)/sqrt(1-bar{alpha_t})
}
DDIM实现:采样算法 ¶ x t − 1 = α ˉ t − 1 ⋅ x t − 1 − α ˉ t ϵ θ ( t ) ( x t ) α ˉ t + 1 − α ˉ t − 1 − σ t 2 ϵ θ ( t ) ( x t ) + σ t ϵ \mathbf{x}_{t-1} = \sqrt{\bar{\alpha}_{t-1}} \cdot \frac{\mathbf{x}_t - \sqrt{1-\bar{\alpha}_t}\boldsymbol{\epsilon}_\theta^{(t)}(\mathbf{x}_t)}{\sqrt{\bar{\alpha}_t}} + \sqrt{1-\bar{\alpha}_{t-1}-\sigma_t^2}\boldsymbol{\epsilon}_\theta^{(t)}(\mathbf{x}_t) + \sigma_t\boldsymbol{\epsilon} x t − 1 = α ˉ t − 1 ⋅ α ˉ t x t − 1 − α ˉ t ϵ θ ( t ) ( x t ) + 1 − α ˉ t − 1 − σ t 2 ϵ θ ( t ) ( x t ) + σ t ϵ σ t ( η ) = η ⋅ ( 1 − α ˉ t α ˉ s ) 1 − α ˉ s 1 − α ˉ t \sigma_t(\eta) = \eta \cdot \sqrt{\left(1-\frac{\bar{\alpha}_t}{\bar{\alpha}_s}\right)\frac{1-\bar{\alpha}_s}{1-\bar{\alpha}_t}} σ t ( η ) = η ⋅ ( 1 − α ˉ s α ˉ t ) 1 − α ˉ t 1 − α ˉ s class DDIM(DDPM):
def __init__(self, eps_model: nn.Module, betas: Tuple[float, float], eta: float, n_T: int, criterion: nn.Module = nn.MSELoss()) -> None:
super(DDIM, self).__init__(eps_model, betas, n_T, criterion)
self.eta = eta
def sample(self, n_sample: int, size, device) -> torch.Tensor:
x_i = torch.randn(n_sample, *size).to(device) # x_T ~ N(0, 1)
for i in range(self.n_T, 1, -1):
eps_t = torch.randn(n_sample, *size).to(device) if i > 1 else 0
eps = self.eps_model(x_i, torch.tensor(i / self.n_T).to(device).repeat(n_sample, 1))
x0_t = (x_i - eps * (1 - self.alphabar_t[i]).sqrt()) / self.alphabar_t[i].sqrt()
sigma = self.eta * ((1 - self.alphabar_t[i] / self.alphabar_t[i - 1]) * (1 - self.alphabar_t[i - 1]) / (1 - self.alphabar_t[i])).sqrt()
c2 = ((1 - self.alphabar_t[i - 1]) - sigma ** 2).sqrt()
x_i = self.alphabar_t[i - 1].sqrt() * x0_t + c2 * eps + sigma * eps_t
return x_i
U-Net实现 ¶ """Simple Unet Structure."""
class Conv3(nn.Module):
def __init__(self, in_channels: int, out_channels: int, is_res: bool = False) -> None:
super().__init__()
self.main = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 3, 1, 1),
nn.GroupNorm(8, out_channels),
nn.ReLU())
self.conv = nn.Sequential(
nn.Conv2d(out_channels, out_channels, 3, 1, 1),
nn.GroupNorm(8, out_channels),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, 3, 1, 1),
nn.GroupNorm(8, out_channels),
nn.ReLU())
self.is_res = is_res
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.main(x)
if self.is_res:
x = x + self.conv(x)
# 假设残差块的输入和输出具有相似的统计特性(例如,零均值和单位方差),
# 那么添加两个这样的信号将导致方差加倍的信号。为了保持方差一致,您除以√2
return x / 1.414
else:
return self.conv(x)
class UnetDown(nn.Module):
def __init__(self, in_channels: int, out_channels: int) -> None:
super(UnetDown, self).__init__()
layers = [Conv3(in_channels, out_channels), nn.MaxPool2d(2)]
self.model = nn.Sequential(*layers)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.model(x)
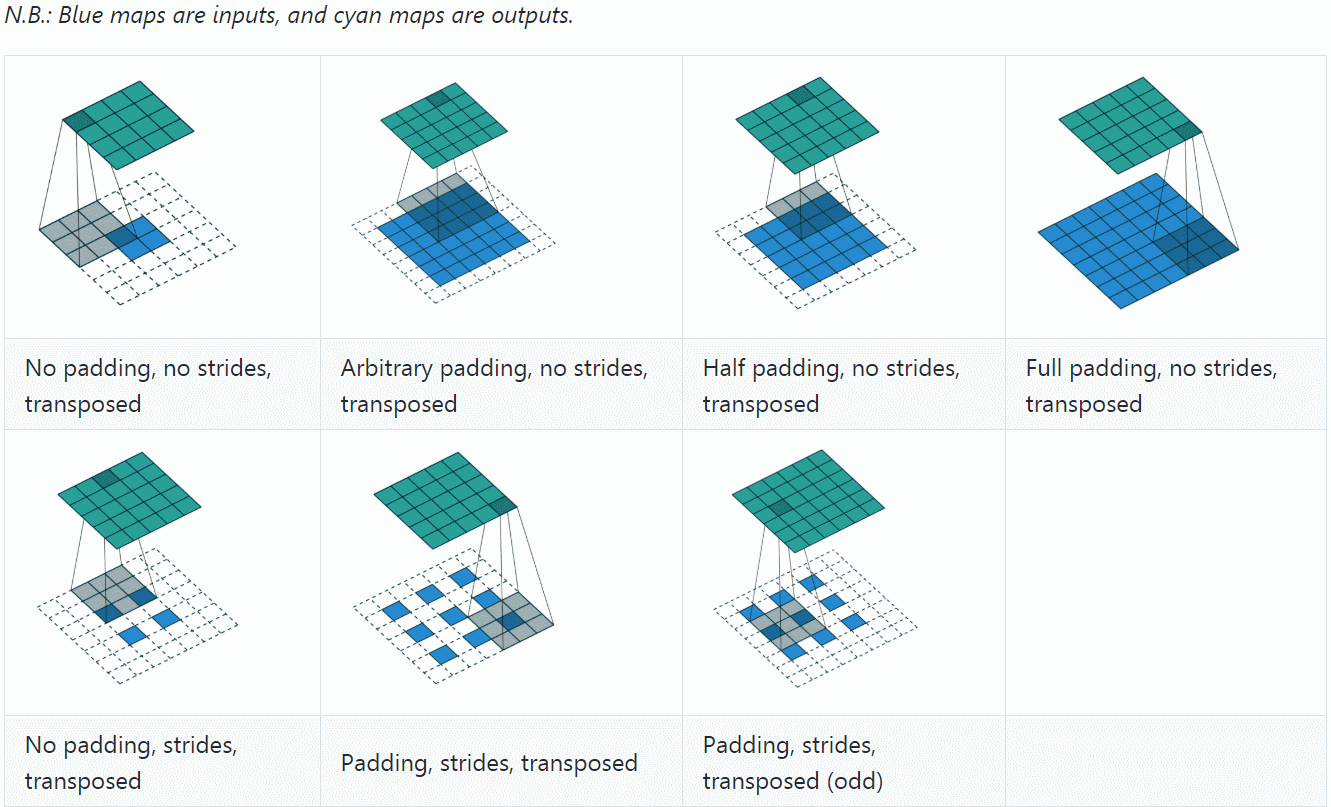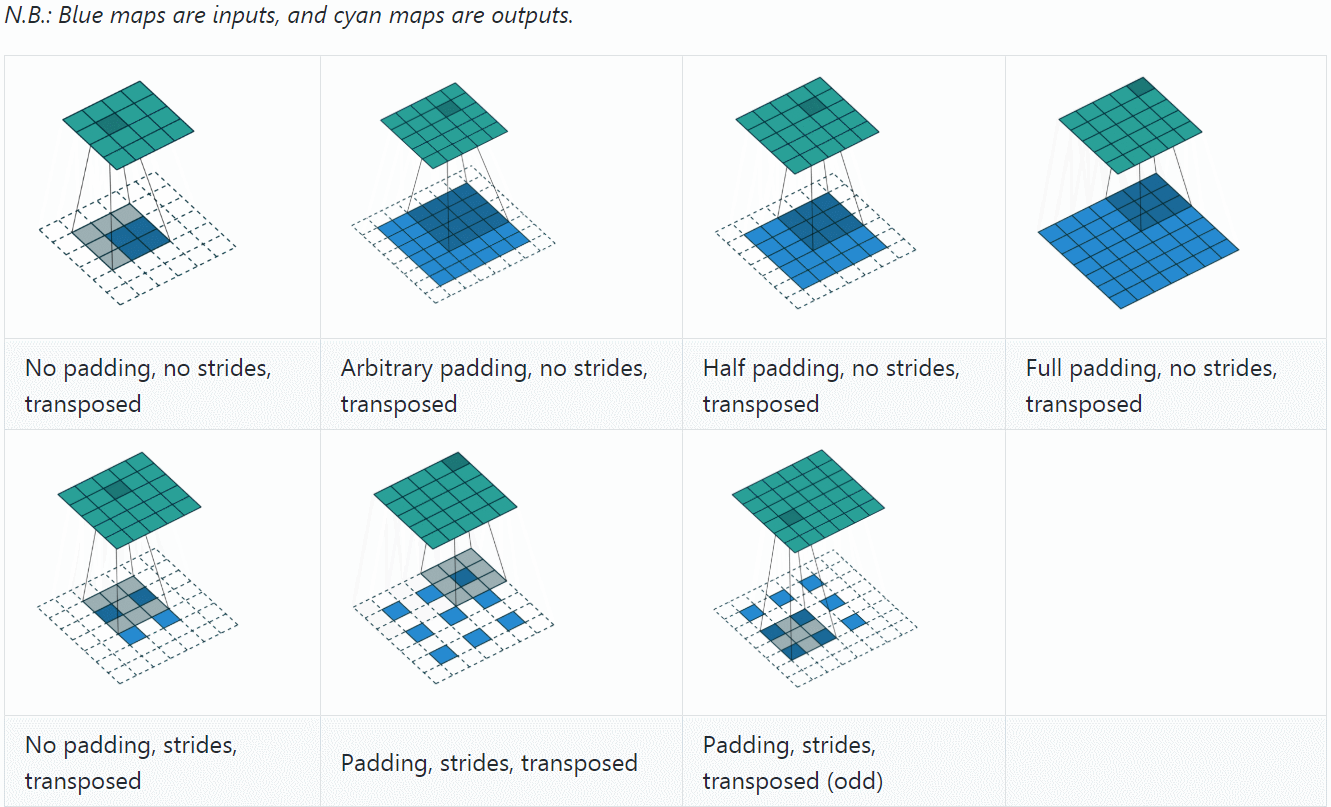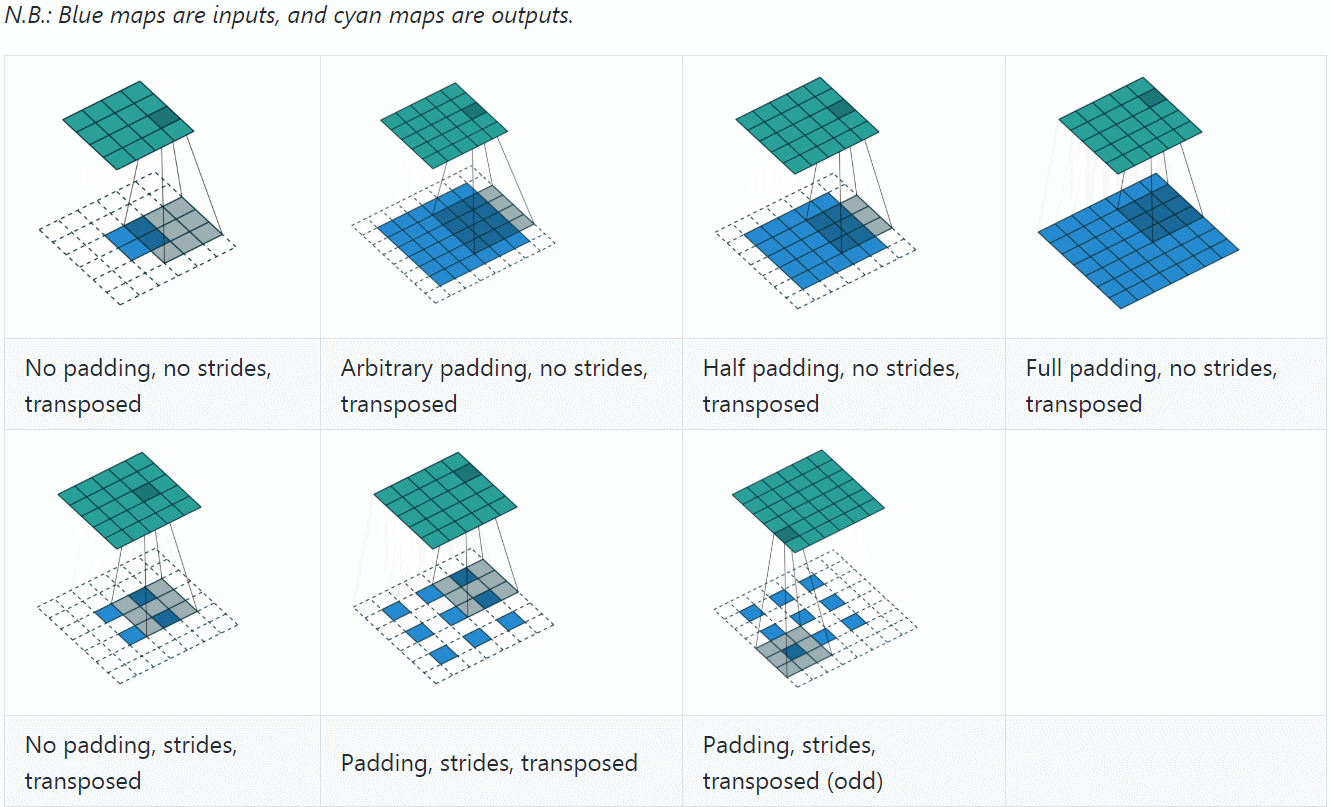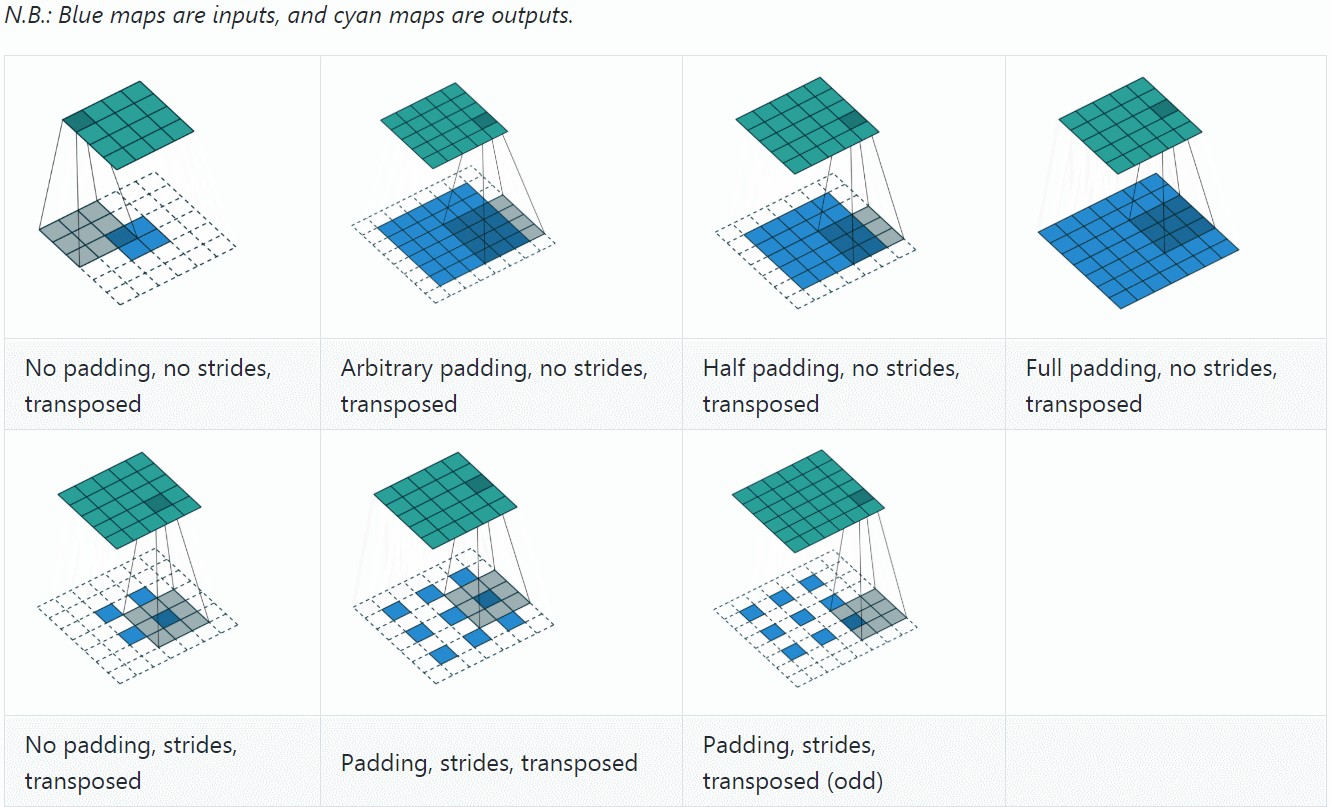
U-Net实现:上采样模块 ¶ 卷积将各个像素中传播的信息累加到一个像素,而逆卷积则将一个像素中存在的信息传播到各个像素。
class UnetUp(nn.Module):
def __init__(self, in_channels: int, out_channels: int) -> None:
super(UnetUp, self).__init__()
layers = [
nn.ConvTranspose2d(in_channels, out_channels, 2, 2),
Conv3(out_channels, out_channels),
Conv3(out_channels, out_channels),
]
self.model = nn.Sequential(*layers)
def forward(self, x: torch.Tensor, skip: torch.Tensor) -> torch.Tensor:
x = torch.cat((x, skip), 1)
x = self.model(x)
return x
class TimeSiren(nn.Module):
def __init__(self, emb_dim: int) -> None:
super(TimeSiren, self).__init__()
self.lin1 = nn.Linear(1, emb_dim, bias=False)
self.lin2 = nn.Linear(emb_dim, emb_dim)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = x.view(-1, 1)
x = torch.sin(self.lin1(x)) # sin来捕获周期
x = self.lin2(x)
return x
"""Simple Unet Structure."""
class NaiveUnet(nn.Module):
def __init__(self, in_channels: int, out_channels: int, n_feat: int = 256) -> None:
super(NaiveUnet, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.n_feat = n_feat
self.init_conv = Conv3(in_channels, n_feat, is_res=True)
self.down1 = UnetDown(n_feat, n_feat)
self.down2 = UnetDown(n_feat, 2 * n_feat)
self.down3 = UnetDown(2 * n_feat, 2 * n_feat)
self.to_vec = nn.Sequential(nn.AvgPool2d(4), nn.ReLU())
self.timeembed = TimeSiren(2 * n_feat)
self.up0 = nn.Sequential(
nn.ConvTranspose2d(2 * n_feat, 2 * n_feat, 4, 4),
nn.GroupNorm(8, 2 * n_feat),
nn.ReLU())
self.up1 = UnetUp(4 * n_feat, 2 * n_feat)
self.up2 = UnetUp(4 * n_feat, n_feat)
self.up3 = UnetUp(2 * n_feat, n_feat)
self.out = nn.Conv2d(2 * n_feat, self.out_channels, 3, 1, 1)
def forward(self, x: torch.Tensor, t: torch.Tensor) -> torch.Tensor:
x = self.init_conv(x)
down1 = self.down1(x)
down2 = self.down2(down1)
down3 = self.down3(down2)
thro = self.to_vec(down3)
temb = self.timeembed(t).view(-1, self.n_feat * 2, 1, 1)
thro = self.up0(thro + temb)
up1 = self.up1(thro, down3) + temb
up2 = self.up2(up1, down2)
up3 = self.up3(up2, down1)
out = self.out(torch.cat((up3, x), 1))
return out
from typing import Dict, Optional, Tuple
from tqdm import tqdm
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from torchvision.datasets import CIFAR10
from torchvision import transforms
from torchvision.utils import save_image, make_grid
def train_cifar10(n_epoch: int = 10, device: str = "cuda:0", load_pth: Optional[str] = None) -> None:
# ddpm = DDPM(eps_model=NaiveUnet(3, 3, n_feat=128), betas=(1e-4, 0.02), n_T=1000)
ddpm = DDIM(eps_model=NaiveUnet(3, 3, n_feat=128), betas=(1e-4, 0.02), eta=0.3, n_T=200)
if load_pth is not None:
ddpm.load_state_dict(torch.load("../../../data/diffusion_contents/ddpm_cifar.pth"))
ddpm.to(device)
tf = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
dataset = CIFAR10(
"../../../dataset/cifar10",
train=True,
download=True,
transform=tf)
dataloader = DataLoader(dataset, batch_size=512, shuffle=True, num_workers=16)
optim = torch.optim.Adam(ddpm.parameters(), lr=1e-5)
for i in range(n_epoch):
print(f"Epoch {i}:")
ddpm.train()
pbar = tqdm(dataloader)
loss_ema = None
for x, _ in pbar:
optim.zero_grad()
x = x.to(device)
loss = ddpm(x)
loss.backward()
if loss_ema is None:
loss_ema = loss.item()
else:
loss_ema = 0.9 * loss_ema + 0.1 * loss.item()
pbar.set_description(f"loss: {loss_ema:.4f}")
optim.step()
ddpm.eval()
with torch.no_grad():
xh = ddpm.sample(8, (3, 32, 32), device)
xset = torch.cat([xh, x[:8]], dim=0)
grid = make_grid(xset, normalize=True, value_range=(-1, 1), nrow=4)
save_image(grid, f"../../../data/diffusion_contents/ddpm_sample_cifar{i}.png")
# save model
torch.save(ddpm.state_dict(), f"../../../data/diffusion_contents/ddpm_cifar.pth")
if __name__ == "__main__":
train_cifar10()
loss: 0.6317: 100%|██████████| 98/98 [00:39<00:00, 2.49it/s]
loss: 0.3541: 100%|██████████| 98/98 [00:38<00:00, 2.52it/s]
loss: 0.2534: 100%|██████████| 98/98 [00:38<00:00, 2.52it/s]
loss: 0.2081: 100%|██████████| 98/98 [00:38<00:00, 2.52it/s]
loss: 0.1876: 100%|██████████| 98/98 [00:39<00:00, 2.51it/s]
loss: 0.1710: 100%|██████████| 98/98 [00:39<00:00, 2.51it/s]
loss: 0.1604: 100%|██████████| 98/98 [00:38<00:00, 2.52it/s]
loss: 0.1546: 100%|██████████| 98/98 [00:39<00:00, 2.51it/s]
loss: 0.1469: 100%|██████████| 98/98 [00:38<00:00, 2.51it/s]
loss: 0.1437: 100%|██████████| 98/98 [00:39<00:00, 2.51it/s]
import matplotlib.pyplot as plt
from PIL import Image
import os
# CIFAR-10 class names
cifar10_classes = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
# Load and display the generated images
fig, axes = plt.subplots(2, 5, figsize=(15, 6))
fig.suptitle('DDPM Generated Samples on CIFAR-10', fontsize=16, fontweight='bold')
for i, ax in enumerate(axes.flatten()):
img_path = f'../../../data/diffusion_contents/ddpm_sample_cifar{i}.png'
if os.path.exists(img_path):
img = Image.open(img_path)
ax.imshow(img)
ax.set_title(f'Class {i}: {cifar10_classes[i]}', fontsize=10)
ax.axis('off')
plt.tight_layout()
plt.show()DALL-E 2:文本到图像生成 ¶ Imagen:高质量文本到图像生成 ¶ Video Diffusion:文本到视频生成 ¶ 文本生成3D模型:Dreamfusion ¶ Diffusion-QL:离线强化学习 ¶ 甚至适用于 RL !
本章系统地介绍了扩散模型(Diffusion Models)的理论基础、改进方法、实现细节和应用场景。
核心概念 ¶ 去噪扩散概率模型(DDPM) 是扩散模型的基础框架,包含两个过程:
训练目标 :简化损失函数通过预测噪声 ϵ \boldsymbol{\epsilon} ϵ
L simple = E t , x 0 , ϵ [ ∥ ϵ − ϵ θ ( x t , t ) ∥ 2 ] L_{\text{simple}} = \mathbb{E}_{t, \mathbf{x}_0, \boldsymbol{\epsilon}}\left[\|\boldsymbol{\epsilon} - \boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t)\|^2\right] L simple = E t , x 0 , ϵ [ ∥ ϵ − ϵ θ ( x t , t ) ∥ 2 ] 模型改进 ¶ 改进方法 核心思想 优势 DDIM 非马尔可夫采样过程 加速采样(50-100步 vs 1000步) IDDPM 学习方差 Σ θ \boldsymbol{\Sigma}_\theta Σ θ 提升对数似然 分类器引导 利用分类器梯度引导采样 提高生成保真度 无分类器引导 联合训练条件/无条件模型 无需额外分类器 隐扩散模型 在潜在空间进行扩散 降低计算成本
关键公式 ¶ Score 函数与噪声预测的关系 :
∇ x t log p ( x t ) = − ϵ θ ( x t , t ) 1 − α ˉ t \nabla_{\mathbf{x}_t} \log p(\mathbf{x}_t) = -\frac{\boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t)}{\sqrt{1-\bar{\alpha}_t}} ∇ x t log p ( x t ) = − 1 − α ˉ t ϵ θ ( x t , t ) 分类器引导的采样 :
ϵ ˉ θ ( x t , t ) = ϵ θ ( x t , t ) − w 1 − α ˉ t ∇ x t log p ϕ ( y ∣ x t ) \bar{\boldsymbol{\epsilon}}_\theta(\mathbf{x}_t, t) = \boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t) - w\sqrt{1-\bar{\alpha}_t} \nabla_{\mathbf{x}_t} \log p_\phi(y|\mathbf{x}_t) ϵ ˉ θ ( x t , t ) = ϵ θ ( x t , t ) − w 1 − α ˉ t ∇ x t log p ϕ ( y ∣ x t ) 无分类器引导 :
ϵ ~ θ ( x t , t , y ) = ( 1 + w ) ϵ θ ( x t , t , y ) − w ϵ θ ( x t , t ) \tilde{\boldsymbol{\epsilon}}_\theta(\mathbf{x}_t, t, y) = (1+w)\boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t, y) - w\boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t) ϵ ~ θ ( x t , t , y ) = ( 1 + w ) ϵ θ ( x t , t , y ) − w ϵ θ ( x t , t ) 实现要点 ¶ U-Net 架构 :扩散模型通常采用 U-Net 作为噪声预测网络,结合时间嵌入、残差块和注意力机制
方差调度 :线性或余弦调度控制噪声添加的节奏
条件生成 :通过交叉注意力机制融入文本、类别等条件信息
典型应用 ¶ 文本到图像 :DALL-E 2、Imagen、Stable Diffusion
文本到视频 :Video Diffusion Models
3D 生成 :DreamFusion、Magic3D
强化学习 :Diffusion-QL
与其他生成模型的对比 ¶ 特性 扩散模型 GAN VAE 训练稳定性 ✓ 稳定 ✗ 模式坍塌 ✓ 稳定 样本质量 ✓ 高质量 ✓ 高质量 △ 模糊 采样速度 ✗ 慢(需迭代) ✓ 快 ✓ 快 多样性 ✓ 高 △ 有限 ✓ 高 对数似然 ✓ 可计算 ✗ 不可计算 △ 下界
扩散模型凭借其稳定的训练过程、高质量的生成结果和灵活的条件控制能力,已成为当前最具影响力的生成模型范式之一。