无损压缩
无损压缩算法在不丢失任何信息的情况下减小文件大小,这意味着可以从压缩文件中完美地重建原始数据。这些方法主要通过识别和消除统计冗余来工作。在本节中,我们将探讨几种基本的无损技术,包括熵编码方法,如霍夫曼编码和算术编码,以及基于字典的方法,如行程长度编码(RLE)和LZW编码。

熵编码 - 信息熵¶
熵编码技术:这类编码技术基于信息论对图像进行重新编码。通常的做法是,为出现概率较高的符号赋予较短的编码,为出现概率较低的符号赋予较长的编码,以确保平均编码长度最短。主要的编码方法包括霍夫曼编码、香农编码和算术编码。
熵编码的基础是信息熵:
其中 是一个离散变量, 是所有可能的状态, 是特定状态 出现的概率, 指的是表示该状态所需的信息量。信息熵是一个理论值,它表征了数据集或序列所需的最佳编码长度,各种熵编码算法从不同角度逼近这个理论值。
霍夫曼编码¶
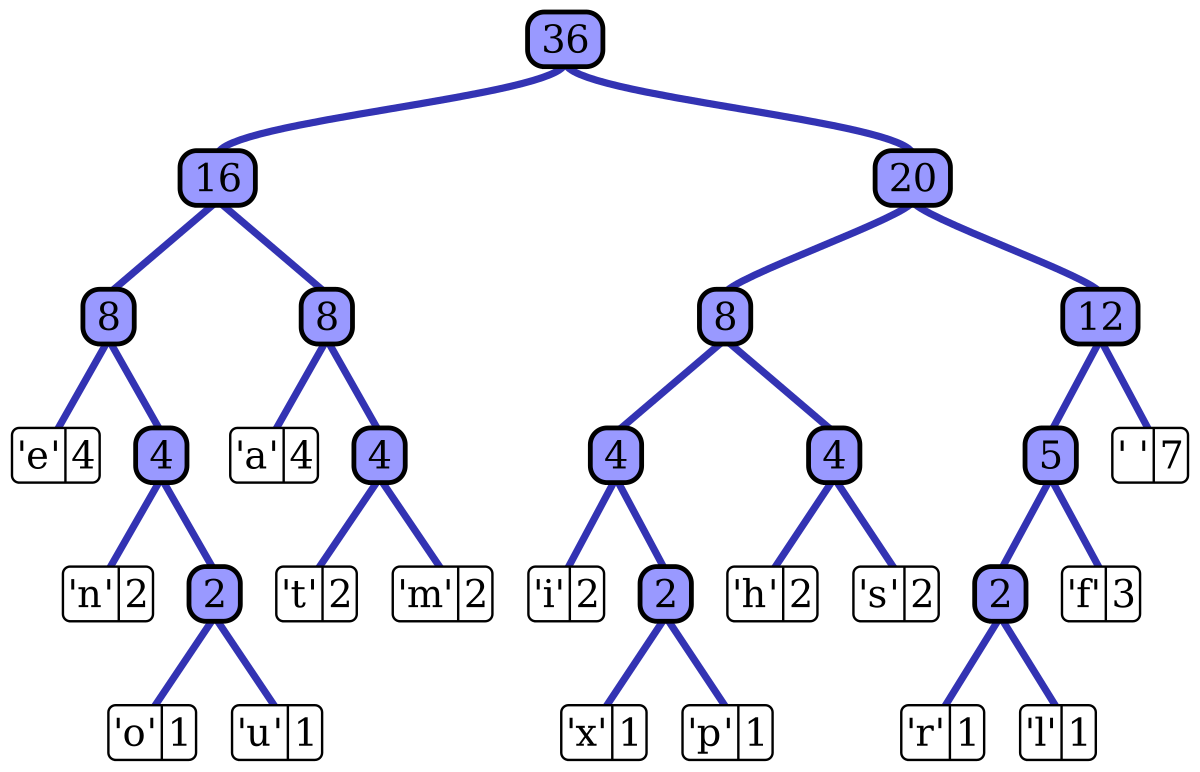
霍夫曼编码 1951年,麻省理工学院的学生霍夫曼面临着期末的头痛问题。老师告诉他,如果他能完成一个令老师满意的期末项目,他就不需要参加考试。
霍夫曼决定选择一个期末项目!报告的题目是“寻找最高效的二进制编码”。
不久之后,霍夫曼交出了一份题为“也许是最好的二进制编码”的期末项目报告,老师看完后皱起了眉头:“标题不好,你得去掉‘也许’。”
| 字符 | 频率 | 编码 |
|---|---|---|
| space | 7 | 111 |
| a | 4 | 10 |
| e | 4 | 0 |
| f | 3 | 1101 |
| h | 2 | 1010 |
| i | 2 | 1000 |
| m | 2 | 111 |
| n | 2 | 10 |
| s | 2 | 1011 |
| t | 2 | 110 |
| l | 1 | 11001 |
| o | 1 | 110 |
| p | 1 | 10011 |
| r | 1 | 11000 |
| u | 1 | 111 |
| x | 1 | 10010 |

霍夫曼编码 - 可变长度编码¶

霍夫曼编码是一种可变长度编码。基本方法是首先扫描图像数据,计算各种像素的出现概率,并根据概率指定不同长度的唯一码字,从而获得霍夫曼码表。编码图像的像素是码字,码字与实际像素值之间的对应关系记录在码表中。
接下来,我们将以右图为例,介绍霍夫曼编码的步骤。
霍夫曼编码 - 构建树 (1)¶

1.统计出每个灰度值出现的频率:
灰度值: 0, 1, 2, 3, 4
出现频率:1/16,1/16, 7/16, 3/16, 4/16
2.从左到右把上述频率按从小到大的顺序排列:
灰度值: 0, 1, 3, 4, 2
出现频率:1/16,1/16, 3/16, 4/16, 7/16
3.选出频率最小的两个值(1/16,1/16)作为二叉树的两个叶子节点,将频率和2/16作为它们的根节点,新的根节点再参与其他频率排序:
灰度值: (0,1), 3, 4, 2
出现频率:2/16,3/16, 4/16, 7/16
霍夫曼编码 - 构建树 (2)¶

4.选出频率最小的两个值(2/16,3/16)作为二叉树的两个叶子节点,将频率和5/16作为它们的根节点,新的根节点再参与其他频率排序:
灰度值: (0,1,3), 4, 2
出现频率:5/16, 4/16, 7/16
5.选出频率最小的两个值(4/16,5/16)作为二叉树的两个叶子节点,将频率和9/16作为它们的根节点,新的根节点再参与其他频率排序:
灰度值: (0,1,3,4,2), 2
出现频率:9/16, 7/16
霍夫曼编码 - 构建树 (3)¶

6.最后,两个频率值(7/16,9/16)作为二叉树的两个叶子节点,将频率和1作为它们的根节点:
灰度值: (0,1,3,4,2)
出现频率: 16/16
7.分配码字。将形成的二叉树的左节点标0,右节点标1。把从最上面的根节点到最下面的叶子节点途中遇到的0,1序列串起来,就得到各级灰度的编码:
灰度值: 2, 4, 3, 1, 0
编码: 0, 10, 111 1101 1100
霍夫曼编码 - 算法总结¶
Figure 8:展示霍夫曼树逐步构建过程的动画。该算法迭代地合并频率最低的节点,直到形成一个完整的二叉树,其中从根到叶的每条路径代表该符号的最优可变长度编码。
霍夫曼编码的基本步骤可以总结为:
将待考虑的像素值按概率排序,并将概率最低的像素符号合并为一个符号。
对每个源像素进行编码,从出现概率最小的像素符号开始,继续对图像中的所有元素进行编码。
霍夫曼编码 - 示例¶
import numpy as np
import queue
# 定义待编码的图像
image = np.array([[3, 1, 2, 4], [2, 4, 0, 2], [2, 2, 3, 3], [2, 4, 4, 2]])
# 计算每个元素的概率
hist = np.bincount(image.ravel(), minlength=5)
probabilities = hist / np.sum(hist)
def get_smallest(data): # 在数据中查找最小的元素
first = second = 1
fid = sid = 0
for idx, element in enumerate(data):
if element < first:
second = first;sid = fid
first = element;fid = idx
elif element < second and element != first:
second = element
sid = idx
return fid, first, sid, second
class Node: # 定义霍夫曼树节点
def __init__(self):
"""
元素值存储在叶节点中
"""
self.prob = None;self.code = None
self.data = None;self.left = None
self.right = None
def __lt__(self, other):
"""
定义优先队列中的排序规则
:param other:
:return:
"""
if self.prob < other.prob:
return 1
else:
return 0
def __ge__(self, other):
if self.prob >= other.prob:
return 1
else:
return 0
# 构建霍夫曼树
def tree(probabilities):
prq = queue.PriorityQueue()
for color, probability in enumerate(probabilities):
leaf = Node()
leaf.data = color
leaf.prob = probability
prq.put(leaf)
while prq.qsize() > 1:
new_node = Node()
l = prq.get()
r = prq.get()
# 找到叶节点中两个最小的概率
# 移除两个最小的节点
new_node.left = l # 左侧是较小的一个
new_node.right = r
new_prob = l.prob + r.prob # 新概率是两个小概率之和
new_node.prob = new_prob
prq.put(new_node) # 插入新节点以替换原来的两个节点
return prq.get() # 返回根节点,完成树的构建
def huffman_traversal(root_node, code_array, f, count): # 遍历霍夫曼树以获取编码
if root_node.right is not None:
code_array[count] = 1
huffman_traversal(root_node.right, code_array, f,count+1)
if root_node.left is not None:
code_array[count] = 0
huffman_traversal(root_node.left, code_array, f,count+1)
else: # 获取每个元素的编码值
huffman_traversal.output_bits[root_node.data] = count
bit_stream = ''.join(str(cell) for cell in code_array[0:count])
color = str(root_node.data)
wr_str = color + ' ' + bit_stream + '\n'
f.write(wr_str)
print(wr_str)
return
root_node = tree(probabilities)
code_array = np.ones([4], dtype=int)
huffman_traversal.output_bits = np.empty(5, dtype=int) # 为huffman_traversal函数添加属性
f = open('code.txt', 'w')
huffman_traversal(root_node, code_array, f, 0)
3 111
1 1101
0 1100
4 10
2 0
霍夫曼编码 - 复杂度分析¶
霍夫曼编码
霍夫曼编码的目标是最小化平均编码长度,即 。霍夫曼编码属于贪心算法。每次选择概率最高的符号分配最短的码长,期望得到最优的码长。
霍夫曼编码算法的复杂度为 。当符号数量较少时,例如英文字母的编码,它相当高效。但当符号数量庞大时,霍夫曼编码的计算复杂度会呈指数级增长。
算术编码 - 简介¶
假设某一符号的出现概率为0.999,根据信息熵,这类符号的信息量为 。如果发送1000个这样的符号,所需的理论编码量为1.44比特。而使用霍夫曼编码,最短的编码长度为1比特,发送1000个这样的符号至少需要1000比特。与霍夫曼编码不同,算术编码生成非块状编码,每个符号的平均编码长度可以是小数。
在算术编码中,源符号和码字之间不存在一一对应的关系。相反,整个源符号序列(或消息)被分配一个单一的算术码字。该码字本身定义了0和1之间的一个实数区间。
算术编码 - 区间表示¶
随着消息中符号数量的增加,用于表示它的区间变得越来越小,而表示该区间所需的信息单位(例如比特)的数量变得越来越大。
算术编码方法:通过一系列递归的区间编码,将源消息表示为实数轴上0-1之间一个逐渐减小的区间码。随着消息变长,编码表示的区间变得更小,也就是说,这个区间需要更多的比特来表示。
算术编码 - 算法步骤 (1)¶
算术编码的步骤如下:
对于一组源符号,根据符号的概率进行排序,并假设消息占据整个半开区间[0, 1),记为当前区间。根据每个源符号的概率,按比例将当前区间细分为子区间。
将消息符号编码为子区间,设置当前符号(初始选择第一个符号),计算当前符号在当前区间中的子区间,将此子区间作为新的当前区间,并将当前区间起点的数值加到编码输出数中。当前符号设置为下一个。
算术编码 - 算法步骤 (2)¶

继续根据每个源符号的概率,按比例细分当前区间中的子区间。然后重复第二步,直到输入消息序列被完全编码。
最终的编码输出数就是算术码。
这里,对来自四码符号信源的五符号消息序列 进行编码。

算术编码 - 编码示例¶

下面以符号序列baacc为例,对算术编码过程进行演示。 1.计算信源中各符号出现的概率。
2.将数据序列中的各数据符号在区间内的间隔(赋值范围)设定为, 即对第个符号,其区间起始位为,其区间终止位为整个区间前闭后开。
3.第一个被压缩的符号为"b",其初始间隔为。

算术编码 - 逐次求精¶

5.第三个被压缩的符号为"a",由于前面的符号"a"的取值区间被限制在范围,所以"a"的取值范围应在前一符号间隔的子区间内。
起始位为
终止位为
即"a"的实际编码区间为。
6.第四个被压缩的符号为"c",其取值范围应在前一符号间隔的子区间内。
起始位为
终止位为
即"c"的实际编码区间为。


算术编码 - 实现问题¶
在算术编码中需要注意三个问题:
由于实际计算机的精度不可能是无限的,运算中的溢出是一个明显的问题。这个问题通常可以通过使用缩放方法和舍入策略来解决。缩放策略在根据符号概率对其进行细分之前,将每个子区间重新归一化到[0, 1)的范围。舍入策略保证了与有限精度算术相关的截断不会妨碍编码子区间的精确表示。
算术编码器只为整个消息生成一个码字,即区间[0,1)内的一个实数,因此解码器在接收到表示该实数的所有比特之前无法进行部分解码。
算术编码器是一种对错误敏感的方法,如果一个比特出错,整个消息将被错误翻译。
算术编码 - 静态与自适应¶
算术编码可以是静态的或自适应的。在静态算术编码中,源符号的概率是固定的。在自适应算术编码中,源符号的概率根据符号在编码过程中出现的频率动态修改。
行程长度编码 - 简介¶
行程长度编码(RLE)将相同强度的连续像素表示为行程长度对,其中每个行程长度对指定了新强度的开始以及具有该强度的连续像素数。其基本思想是在扫描线中使用两个字段来表示具有相同颜色值的相邻像素:
第一个字段表示像素重复的次数;
第二个字段表示像素的值。
例如:RRRRRGGBBBBBB->5R2G6B
行程长度编码 - 二值图像¶
行程长度编码在压缩二值图像时特别有效。因为只有两种可能的强度(黑色和白色),相邻像素更有可能是相同的。
对二进制数进行编码,假设黑色代表0,白色代表1,我们对十进制数312491进行行程长度编码。它将被表示为3(11), 12(1100), 4(100), 9(1001), 1(1),并将它们连接起来为11110010010011,但这样的编码无法确定单个码字的起始点。
行程长度编码 - 编码方案¶

3的编码为11-1=10(从1开始编码,所以减去1),而12的编码为11OO-1=1011,加上首部110,则12的编码为1101011。整个二值序列的编码为0101101011011110100OOO0。
行程长度编码 - 解码示例¶


def encode(string): # 编码函数
if string == '':
return ''
i = 0
count = 0
letter = string[i]
rle = []
while i <= len(string) - 1:
while i < len(string) and string[i] == letter:
i += 1
count += 1
if count == 1:
rle.append('{0}'.format(letter))
else:
rle.append('{0}{1}'.format(count, letter))
if i > len(string) - 1:
break
letter = string[i]
count = 0
final = ''.join(rle)
return final
def decode(string): # 解码函数
if string == '':
return ''
import re
multiplier = 1 # 默认值改为1,处理单个字符的情况
count = 0
rle_decoding = []
rle_encoding = re.findall(r'\d+|[A-Za-z]|[\w\s]', string) # 修复正则表达式
for item in rle_encoding:
if item.isdigit():
multiplier = int(item)
elif item.isalpha() or item.isspace():
while count < multiplier:
rle_decoding.append('{0}'.format(item))
count += 1
multiplier = 1 # 重置为1而不是0
count = 0
return ''.join(rle_decoding)
# 测试函数
test_string = "AAABBBCCCC"
encoded = encode(test_string)
decoded = decode(encoded)
print(f"原始: {test_string}")
print(f"编码后: {encoded}")
print(f"解码后: {decoded}")
原始: AAABBBCCCC
编码后: 3A3B4C
解码后: AAABBBCCCC
LZW编码 - 简介¶
LZW(Lempel-Ziv-Welch)无损压缩解决了图像中空间冗余的去除问题,它不需要先验知识,即待编码符号的出现概率。
LZW压缩算法提取原始文本文件数据中的不同字符,根据这些字符创建一个字典,然后用字典中字符的索引替换相应的字符,以减小原始数据的大小。LZW压缩算法的字典不是预先创建的,而是根据原始文件数据动态创建的,在解码时从编码数据中恢复一个相同的解压字典。
LZW编码 - 字典结构¶
LZW算法基于一个字典T,它将输入字符串映射为一个定长(通常为12位)的码字。
可能的编码有 种, 种表示单个字符,剩下的3840种分配给压缩过程中出现的字符串。
编码过程可以看作是一个查表过程。如果表中存在匹配的字符串,则输出该字符串数据在表中的索引,否则将该字符串插入表中并输出新的索引。
LZW编码 - 算法步骤¶
LZW算法的基本步骤如下:
字典初始化为包含所有可能的单字字符,前缀字符串P(Prefix)初始化为空。
当前字符C(Current)是字符流中的下一个字符。
判断前缀字符串加上当前字符(即P+C)是否在字典中,
a. 如果是,则将当前字符添加到前一个字符串并扩展它,即P=P+C
b. 如果不是,则输出字符串P中的前缀码字,将P+C添加到字典中,并使当前字符成为前缀字符串P=C。
判断字符流中是否还有需要处理的字符。如果有,则重复步骤2,如果没有,则输出前缀字符串P的码字,然后终止。
LZW编码 - 示例可视化¶
Figure 19:逐步演示LZW编码过程的动画。该算法在处理输入字符串时动态构建字典,用更短的编码替换重复的模式以实现压缩。
LZW编码 - 实现¶
LZW编码过程的模拟如下:
string = ' wabbawabba '
dictionary = {'a': 1, 'b': 2, 'w': 3}
last = 4
p = ""
result = []
for c in string:
pc = p + c
# 判断前缀字符串 + 当前字符是否在字典中
if pc in dictionary:
p = pc # 将当前字符扩展到前一个字符串
else:
# 将前缀字符串附加到输出
if p != '':
result.append(dictionary[p])
# 将P+C添加到字典中
dictionary[pc] = last
last += 1
# 将当前字符赋给前缀字符串
p = c
if p != '':
result.append(dictionary[p])
print(result)
[4, 3, 1, 2, 2, 1, 6, 8, 1, 4]