有损压缩
有损压缩通过永久丢弃原始文件中的部分数据来实现更高的压缩比。其核心思想是移除人类视觉系统不太能感知到的信息,从而得到一个视觉上与原始图像非常相似但不完全相同的重建图像。本章涵盖了关键的有损技术,包括预测编码(如DPCM),它对样本之间的差异进行编码;以及变换编码(以离散余弦变换或DCT为特色),它将图像能量集中到少数几个可以被有效量化的系数中。最后,我们将看到这些概念是如何在广泛使用的JPEG压缩标准中结合起来的。
预测编码¶

预测编码 - 简介¶
预测编码数据压缩技术可以在没有显著计算开销的情况下实现良好的压缩,并且可以是有损的或无损的。该方法通常基于信号数据的相关性。它使用先前的样本值,根据模型估计来预测新的样本,最终通过仅提取和编码新信息来消除空间和时间域中数据的相关性冗余。新信息被定义为实际值与预测值之间的差值。
在二维预测编码中,预测是图像从左到右、从上到下扫描过程中先前像素的函数。也就是说,预测是通过利用其相邻像素的相关性来进行的。
预测编码 - 无损系统¶

预测编码
无损预测编码系统的基本组件包括一个编码器和一个解码器,每个都包含一个相同的预测器。随着离散时间输入信号 的连续样本被引入编码器,预测器根据指定数量的过去样本生成每个样本的预期值。预测器的输出然后被四舍五入到最接近的整数,表示为 ,并用于形成差值或预测误差:
该误差使用可变长度编码进行编码,以生成压缩数据流的下一个元素。
预测编码 - 线性预测器¶

预测编码
解码器从接收到的可变长度码字中解码出 ,并执行逆运算
为了解压或重建原始输入序列,可以使用各种局部、全局和自适应方法来生成 。在许多情况下, 预测是作为 个先前样本的线性组合形成的:
其中 是线性预测器的阶数, 是一个用于 四舍五入到最接近整数的函数,而 是预测系数。
线性预测器 - 图示¶

最优线性预测器¶

最优线性预测器
假设一个均值为零、方差为 的平稳信号 在时间 被采样,相应的采样值表示为 。在编码过程中,假设下一个采样值为 ,则 的线性预测 可以根据之前的 个采样值估计为 ,其中 是预测系数。
表示预测值与真实采样值之间的差值。预测编码的本质是编码 ,而不是编码原始样本。
最优线性预测器 - 推导¶

这里的系数 通常通过最小化编码器的均方误差来求解,以获得最优线性预测器。即,求解 的偏导数等于零:
化简左侧: 由于 是有界的,我们可以交换偏导数和期望的顺序。
将偏微分代入零:
任意两个像素的协方差可以表示为 ( 通常是已知的),对于 ,上述方程可以简化为n阶线性方程组:
或矩阵形式:
求解上述线性方程组即可得到系数 。
有损预测编码 - 反馈回路¶

有损预测编码
与无损预测编码不同,有损方法在编码模型中引入了一个额外的量化器。量化器被插入到符号编码器和形成预测误差的点之间。它将预测误差映射到一个有限范围的输出,表示为 ,这决定了压缩量和发生的失真。
为了适应量化步骤的插入,无损编码器必须被修改,以便编码器和解码器生成的预测是等效的。这是通过将有损编码器的预测器置于反馈回路中来实现的,其输入表示为 ,是作为过去预测和相应量化误差的函数生成的。即,
其中 如前所定义。这种闭环配置可防止解码器输出处误差的累积。
有损预测编码 - DM 和 DPCM¶
有损预测编码是仅需简单设备即可实现良好压缩质量的高效编码方法。我们主要介绍两种有损预测编码方法。一种是DM(增量调制)编码,另一种是差分脉冲编码调制DPCM(Differential Pulse Code Modulation)。
增量调制(DM)编码¶

增量调制(DM)编码是一种相对简单的有损预测编码方法。当前时刻的预测值 是由前一时刻的重建信号 得到的,即:
其中 是预测系数。然后根据其符号将预测误差量化为两个级别:
编码和解码过程如下:
编码:
解码:

增量调制(DM) - 结果¶

DPCM编码 - 简介¶
模拟信号到数字信号的转换过程称为脉冲编码调制(PCM),也称为PCM编码。如果直接用PCM对二维信号进行编码,所需的存储空间非常大。
一种更常用的预测编码方法是差分脉冲编码调制(DPCM),它将预测约束为先前样本的线性组合形式。它大大简化了分析,同时降低了预测器的计算复杂度。

DPCM编码 - 步骤概述¶

DPCM编码的基本步骤:
(1) 读取待压缩的图像。
(2) 计算预测器产生的误差。
(3) 量化误差。
DPCM解码的基本步骤:
(1) 接收量化后的误差。
(2) 计算预测值。
(3) 将误差加到预测值上。
DPCM编码 - 示例设置¶

预测公式:
计算任意像素 的误差:
误差量化:在[-255,+255]范围内对误差进行均匀采样 (因为图像的像素值在[0, 255]范围内)以获得量化误差 。
预测更新:量化误差被传输(这里仅存储在数组中)。为了计算误差的下一个值,我们需要通过以下方式更新预测值:
重建信号 需要被存储,用于后续的信号预测。

import numpy as np
from skimage import data
from skimage import transform
from matplotlib import pyplot as plt
import math
# 配置中文字体支持(与 filtering.ipynb 一致)
plt.rcParams['font.sans-serif'] = [
'Noto Sans CJK SC', 'Noto Sans CJK JP', 'SimHei',
'Microsoft YaHei', 'WenQuanYi Micro Hei', 'DejaVu Sans'
]
plt.rcParams['axes.unicode_minus'] = False
# 均匀量化误差
def quantize_error (error, level):
max=255
min=-255
q= (max-min)/level
i=1
while (error>=min+q*i):
i=i+1
quantized_error=min+q*(i-1)+q/2
return quantized_error
def DPCM_encoder (img,level):
N=img.shape[0]
predictor=np.zeros(shape=(N, N))
quantized_error=np.zeros(shape=(N, N))
# 我们读取图像的第1行、第1列,第2行、第2列,第3行……因为预测器使用前一行和前一列的相邻元素
for i in range (N):
# 读取第j行
for j in range (N):
if i==0:
if j==0:
predicted = 0
else:
predicted = 0.95*predictor[i,j-1]
else:
predicted=0.95*predictor[i-1,j]+0.95*predictor[i,j-1]-0.95**2*predictor[i-1,j-1]
error=img[i,j]-predicted
quantized_error[i,j]=quantize_error(error,level)
predictor[i,j]=predicted+quantized_error[i,j]
return quantized_error
def DPCM_decoder(error):
N=error.shape[0]
img=np.zeros(shape=(N, N))
predictor=np.zeros(shape=(N, N))
for i in range (N):
for j in range (N):
if i==0:
if j==0:
predicted=0
else:
predicted=0.95*predictor[i,j-1]
else:
predicted=0.95*predictor[i-1,j]+0.95*predictor[i,j-1]-0.95**2*predictor[i-1,j-1]
img[i,j]=predicted+error[i,j]
predictor[i,j]=predicted+error[i,j]
return img
if __name__ == '__main__':
# 16级量化
levels=16
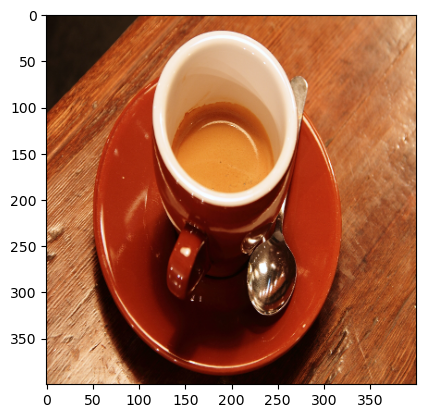
img=data.coffee()
img=transform.resize(img,(img. shape [0],img.shape [0],3), preserve_range=True)
plt.imshow(img/255.0)
plt.show()
img_r = img[:,:,0]
encoded_img_r=DPCM_encoder(img_r,levels)
decoded_img_r=DPCM_decoder(encoded_img_r)
decoded_img_r=decoded_img_r.reshape((decoded_img_r.shape[0], decoded_img_r.shape [1],1))
img_g = img[:, :, 1]
encoded_img_g = DPCM_encoder(img_g, levels)
decoded_img_g = DPCM_decoder(encoded_img_g)
decoded_img_g = decoded_img_g.reshape((decoded_img_g.shape[0],decoded_img_g.shape[1],1))
img_b = img[:, :, 2]
encoded_img_b = DPCM_encoder(img_b, levels)
decoded_img_b = DPCM_decoder(encoded_img_b)
decoded_img_b = decoded_img_b.reshape((decoded_img_b.shape [0],decoded_img_b.shape[1],1))
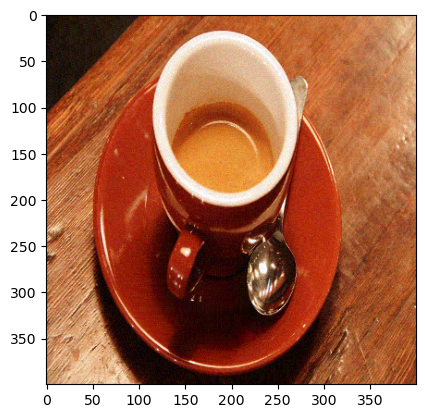
decoded_img = np.concatenate([decoded_img_r,decoded_img_g, decoded_img_b], 2)
decoded_img = np.clip(decoded_img/255.0,0.0,1.0)
plt.imshow(decoded_img)
plt.show ()

块变换编码 - 简介¶
块变换编码将图像分割成大小相等、不重叠的小块,并使用二维变换独立处理这些块。它不直接对空间图像信号进行编码,而是首先将空间图像信号变换到另一个正交向量空间(变换域),生成一批变换系数,然后对这些变换系数进行编码。
在时域或空域中描述数据时,数据的相关性和冗余度非常高。变换编码将数据转换到不同的变换域,在该域中,数据的相关性和冗余度将大大降低。由于系数是独立的,量化后的编码可以实现更大的压缩比。

块变换编码 - 最优变换¶
变换是变换编码的核心。理论上,理想的变换应该使信号在变换域中的样本在统计上相互独立。
通常不可能找到一个可逆变换来产生统计上独立的样本,而是只能要求信号在变换域中的样本是线性独立的。这也称为最优变换。正交变换可以使样本线性独立,它可以分为非正弦类和正弦类:
非正弦变换以沃尔什变换、哈尔变换、斜变换等为代表。优点是计算开销小,但它们的基向量很少能反映物理信号的机理和结构特性,变换效果不理想。
正弦变换以离散傅里叶变换、离散正弦变换、离散余弦变换等为代表。其最大的优点是具有趋于最优变换的渐近性质。
KL变换¶
Karhunen–Loève (KL) 变换,也称为霍特林变换,是一种特征分解变换或主成分方法。
KL变换可以使原始多波段图像经过变换后提供一组不相关的图像变量。第一主成分方差较大,包含了原始图像的主要信息。因此,如果需要集中表达信息,突出图像的某些细节特征,可以利用主成分变换来实现。
属性¶
KL变换在最小化均方误差方面是最优变换,它在变换域中符合线性正交变换,即满足样本线性独立的要求。通常用作衡量其他变换正交性的标准。
KL变换由信号的相关函数确定。对于平稳过程,当变换区间趋于无穷大时,它趋于一个复指数函数。
特征值分解¶
KL变换的主要思想:
找到数据集主成分的一个子集。
基向量相互正交;该子空间在相关性方面是最优的。
将数据变换到主成分空间,以最小化互相关性。
KL变换与特征值/特征向量有直接关系。对于一个 的矩阵 ,非零特征向量 和特征值 满足
算法步骤¶
KL变换的基本步骤:
对于图像的任意像素向量 ,计算图像的期望值:
计算图像的协方差:
对协方差矩阵进行对角化,对角线上为特征值,列为特征向量: 求解 ,其中 。 由于 是实对称矩阵,
或者用完整的矩阵形式表示:
其中 的列是标准正交的特征向量。我们也可以用 来对角化 。
将图像像素乘以正交变换 ,,以消除像素间的相关性。第一个特征值和特征向量包含了总方差的80%以上。
代码实现¶
import numpy as np
from matplotlib import pyplot as plt
from skimage import data
# 配置中文字体支持(与 filtering.ipynb 一致)
plt.rcParams['font.sans-serif'] = [
'Noto Sans CJK SC', 'Noto Sans CJK JP', 'SimHei',
'Microsoft YaHei', 'WenQuanYi Micro Hei', 'DejaVu Sans'
]
plt.rcParams['axes.unicode_minus'] = False
def im2col(img,block_size): # 将图像分割成大小相等的图像块
image_block = []
block_height = block_size[1]
block_width = block_size[0]
block_size = block_height * block_width
for j in range(0, img.shape[1], block_height):
for i in range(0, img.shape[0], block_width):
image_block.append(np.reshape(img[i:i+block_width, j:j+block_height], block_size))
image_block = np.asarray(image_block).astype(float)
return image_block
def col2im(mtx, image_size, block_size): # 从8x8的子块中恢复图像
p, q = block_size
sx = image_size[1]
sy = image_size[0]
result = np.zeros(image_size)
col = 0
for j in range(0,sx,q):
for i in range(0,sy,p):
result[i:i+q, j:j+p] = mtx[col].reshape(8,8)
col += 1
return result
img = data.camera()
img=img.astype(np.double)
img = img/255
# 将图像分割成8x8的子块
block_height = 8
block_width = 8
block_size = block_width * block_height
n = im2col( img ,( block_width,block_height ))
#KL变换,编码
mean = np.mean(n, 0 ) #计算图像块的均值
image = np.transpose(n) - mean.reshape ((block_size, 1 )) #平移使均值为0
covariance = np.cov(image) #计算图像块的协方差矩阵
#计算协方差矩阵的特征向量和特征值
w,v = np.linalg.eig( np.transpose (covariance))
# 按特征值降序排列特征向量
idx = w.argsort ()[::- 1 ]
w = w[ idx ]
v = v[:, idx ] #v是正交变换矩阵
y = np.matmul(np.transpose (v),image); #执行KL正交变换
n = 5 #这里我们只需要最大的5个分量
#将其余分量置零,即压缩后的数据
y[n:block_size ,:] = np.zeros(( block_size-n,y.shape [ 1 ]))
#KL逆变换,解码
#将压缩后的数据乘以逆正交变换矩阵以恢复图片
z2 = np.matmul( v, y );
x2 = z2 + mean.reshape((block_size, 1 )); #恢复均值
# 子块重新合并成一张图片
img_comp = col2im(np.transpose(x2),(img.shape[0], img.shape[1]),(block_width,block_height ))
#绘制原始图像和恢复后的图像
plt.subplot(1,2,1)
plt.axis('off')
plt.imshow(img,cmap='gray')
plt.title('原始图像')
plt.subplot(1,2,2)
plt.axis('off')
plt.imshow(img_comp,cmap='gray')
plt.title('使用'+str(n)+"个分量的KL解码")
plt.show()
/home/jack/.conda/envs/cv_class/lib/python3.12/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 21407 (\N{CJK UNIFIED IDEOGRAPH-539F}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/jack/.conda/envs/cv_class/lib/python3.12/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 22987 (\N{CJK UNIFIED IDEOGRAPH-59CB}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/jack/.conda/envs/cv_class/lib/python3.12/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 22270 (\N{CJK UNIFIED IDEOGRAPH-56FE}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/jack/.conda/envs/cv_class/lib/python3.12/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 20687 (\N{CJK UNIFIED IDEOGRAPH-50CF}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/jack/.conda/envs/cv_class/lib/python3.12/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 20351 (\N{CJK UNIFIED IDEOGRAPH-4F7F}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/jack/.conda/envs/cv_class/lib/python3.12/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 29992 (\N{CJK UNIFIED IDEOGRAPH-7528}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/jack/.conda/envs/cv_class/lib/python3.12/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 20010 (\N{CJK UNIFIED IDEOGRAPH-4E2A}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/jack/.conda/envs/cv_class/lib/python3.12/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 20998 (\N{CJK UNIFIED IDEOGRAPH-5206}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/jack/.conda/envs/cv_class/lib/python3.12/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 37327 (\N{CJK UNIFIED IDEOGRAPH-91CF}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/jack/.conda/envs/cv_class/lib/python3.12/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 30340 (\N{CJK UNIFIED IDEOGRAPH-7684}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/jack/.conda/envs/cv_class/lib/python3.12/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 35299 (\N{CJK UNIFIED IDEOGRAPH-89E3}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/jack/.conda/envs/cv_class/lib/python3.12/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 30721 (\N{CJK UNIFIED IDEOGRAPH-7801}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)

离散余弦变换 (DCT)¶
离散余弦变换 (DCT) 是数字信号处理中的一项基础技术,尤其适用于图像和音频的有损数据压缩。它是一种数学变换,将信号从其空间域(例如,图像中的像素值)转换到频域表示。与产生复数值系数的离散傅里叶变换 (DFT) 不同,DCT 完全在实数域中操作,这使得它在计算上更简单,对图像处理应用更高效。
DCT 的工作原理是将有限的数据点序列表示为以不同频率振荡的余弦函数之和。这种实值表示消除了对复数算术的需求,与基于 FFT 的方法相比,这既减少了计算开销,也减少了内存需求。
能量集中与去相关¶
DCT 的一个关键特性是其出色的能量集中(或能量压缩)能力。对于大多数自然信号,如图像和音频,DCT 将信号能量的绝大部分集中到少数低频系数中。对应于更精细细节和噪声的高频分量,其能量往往要低得多。这一特性对压缩至关重要,因为它允许对包含较少感知重要信息的高频系数进行激进的量化或消除,而不会导致质量的严重下降。
此外,对于相邻样本之间具有高相关性的信号(这在自然图像中很典型),DCT 能有效地去相关信号。它在这方面的性能接近于 Karhunen-Loève 变换 (KLT),后者在理论上去相关性是最优的,但依赖于数据且计算成本高。DCT 的近乎最优性能,加上其计算效率和固定的基函数,使其成为实际压缩应用的理想选择。
属性与优势¶
数学属性:
DCT 的基向量与托普利兹矩阵的特征向量非常相似,托普利兹矩阵能有效地模拟人类语音和图像等信号的相关结构。
这种与最优 Karhunen-Loève 变换的相似性使 DCT 成为具有高空间相关性信号的近乎最优选择。
计算优势:
仅使用实值运算(无需复数算术)。
存在快速算法,通常复杂度为 O(N log N)。
对自然信号具有出色的能量集中能力。
其特性有助于减少图像块边界处的块效应。
行业采纳:
由于其在性能和计算效率方面的最佳平衡,DCT 已成为许多现代压缩标准的基石。
它被广泛采用于国际标准中,包括:
图像压缩: JPEG
视频压缩: MPEG-1/2/4, H.264/AVC, H.265/HEVC 在这些应用中,8x8 块 DCT 是最常见的实现方式。


可视化¶

编码步骤¶
如果需要,转换色彩空间,并将图像分割成 的块。
对每个块应用前向二维DCT,以获得64个系数:一个DC(平均电平)和63个AC(高频)系数。
量化DCT系数:除以一个量化矩阵,并四舍五入到最近的整数。
量化是图像质量下降的最大原因。量化数据中的DC分量大于AC分量,AC分量包含大量的0。
将量化后的系数以“Z”形排列,从而产生多个连续的零,并通过利用两个相邻的图像块再次压缩数据。最后,变换后的DCT系数被编码和传输。
解码步骤¶
1.在解码过程中,构建一个压缩图像结构,首先解码编码后的量化DCT系数。
2.然后进行逆量化,将DCT系数转换为8×8的样本图像块(使用二维DCT逆变换)。
3.最后,将逆变换后的块组合成单个图像。
DCT - 通用表达式¶

可分离变换:数字图像都是实数矩阵, 令 为 的图像灰度矩阵
为了方便分析和推导,可分离变换可以写成矩阵形式:
二维离散傅里叶变换的可分离变换:
除了离散傅里叶变换,许多其他正交变换也可以用这种形式表示。例如:离散余弦变换、KL变换等。
一维前向与反向¶
一维前向DCT,定义如下:
相应的一维反向DCT:
公式中, 和 的值都在集合 中,其中 定义为:
一维矩阵形式¶
一维DCT可以写成矩阵形式:
其中 是 的原始图像块, 是 的变换域图像块。 是一个 的正交变换矩阵,矩阵中的第 个元素 定义为:
其中 是 的正交变换矩阵:
二维前向与反向¶
一个 块 的二维前向DCT定义为:
相应的反向DCT是:
在这些公式中, 都在集合 中,系数 和 的定义方式与一维情况相同,使用一个通用变量 :
二维DCT的矩阵形式:
其中 是 的空间块, 是 的变换块。 是 由一维DCT基定义的 正交变换矩阵。
DCT基图像¶
DCT将图像表示为基图像的线性组合,其中每个基图像 对应于特定的频率分量。基图像的元素 由基函数定义:
前向DCT: 前向DCT计算每个基图像的系数 。该系数是输入图像 与相应基图像 的内积,并由归一化因子 缩放:
反向DCT: 反向DCT通过对所有基图像求和来重建原始图像 ,每个基图像 由其相应的系数 和归一化因子 加权:
归一化系数 的定义与前一节一致:

DCT仿真¶
from math import cos, pi, sqrt
import numpy as np
from skimage import data
from matplotlib import pyplot as plt
# 配置中文字体支持(与 filtering.ipynb 一致)
plt.rcParams['font.sans-serif'] = [
'Noto Sans CJK SC', 'Noto Sans CJK JP', 'SimHei',
'Microsoft YaHei', 'WenQuanYi Micro Hei', 'DejaVu Sans'
]
plt.rcParams['axes.unicode_minus'] = False
def dct_2d (image, coefficient_percentage=0.0):
height = image.shape[0]
width = image.shape[1]
imageRow = np.zeros_like (image).astype (float)
imageCol = np.zeros_like (image).astype (float)
for h in range (height):
imageRow [h, :] = dct_1d (image [h, :])
for w in range (width):
imageCol[:, w] = dct_1d(imageRow [ :, w])
if coefficient_percentage > 0:
nc = int(height*width*coefficient_percentage)
print(nc)
img = np.abs(imageCol).sum(axis=2)
thres=np.partition(img.ravel(), -nc)[-nc]
imageCol[img<thres,:] = 0
return imageCol
def dct_1d (image):
n = len (image)
newImage = np.zeros_like (image).astype (float)
for k in range (n) :
sum = 0
for i in range(n):
sum += image[i] * cos (2 * pi * k / (2.0 * n)* i + (k * pi) / (2.0 * n))
ck = sqrt (0.5) if k == 0 else 1
newImage[k] = sqrt(2.0/ n) * ck * sum
return newImage
def idct_2d(image):
height = image.shape [0]
width = image.shape [1]
imageRow = np. zeros_like(image).astype(float)
imageCol = np. zeros_like(image).astype(float)
for h in range (height):
imageRow[h, :] = idct_1d (image [h, :])
for w in range (width):
imageCol[:, w] = idct_1d(imageRow[:, w])
return imageCol
def idct_1d(image):
n = len(image)
newImage = np.zeros_like (image).astype (float)
for i in range (n) :
sum = 0
for k in range (n):
ck = sqrt (0.5) if k == 0 else 1
sum += ck * image[k] * cos(2 * pi * k / (2.0 * n) * i + (k * pi) / (2.0 * n))
newImage[i] = sqrt (2.0 / n) * sum
return newImage
image=data.coffee ()
coefficient_percentage=0.1
imgResult = dct_2d(image, coefficient_percentage)
idct_img = idct_2d(imgResult)
plt.subplot(1,3,1)
plt.axis('off')
plt.imshow(image)
plt.subplot(1, 3, 2)
plt.axis('off')
imgResult = (imgResult-imgResult.min())/(imgResult.max()-imgResult.min())
plt.imshow(imgResult)
plt.subplot(1, 3,3)
plt.axis('off')
idct_img = (idct_img-idct_img.min())/(idct_img.max()-idct_img.min())
plt.imshow(idct_img)
plt.show ()
24000

JPEG编码¶
最流行和最全面的连续色调、静止帧压缩标准之一是JPEG标准。JPEG代表联合图像专家组(Joint Photographic Experts Group),是由ISO和ITU-T联合成立的专家组,旨在为静态图像(彩色和灰度图像)制定压缩算法。
它定义了三种不同的编码系统:
基于DCT的有损基线编码系统,适用于大多数压缩应用;
用于更大压缩、更高精度或渐进式重建应用的扩展编码系统;和
用于可逆压缩的无损独立编码系统。
压缩比¶

JPEG的有损基线系统通常被称为顺序基线系统,输入和输出数据精度限制为8位,而量化的DCT值限制为11位。支持多个压缩级别,压缩比通常在1到1之间。压缩比越高,质量越低;相反,压缩比越小,质量越好。
流程概述¶

压缩本身按三个顺序步骤执行:DCT计算、量化和可变长度码分配。

基本步骤如下:
1.首先将整个图像细分为多个8×8的图像块。例如,一个160x160的原始图像可以细分为20×20个8x8的图像块。
每个8×8的图像块进行DCT变换,我们将得到DCT系数:
基函数:
恢复图片:
DCT - 可视化¶
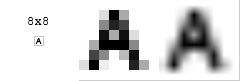
考虑这个8×8的大写字母A的灰度图像,原始尺寸(左),放大10倍 - 最近邻(中),放大10倍 - 双线性(右)。
每个基函数都乘以其系数,然后该乘积被添加到最终图像中。左边是最终图像。中间是加权函数(乘以一个系数),它被添加到最终图像中。右边是当前函数和相应的系数。图像按10倍的比例缩放(使用双线性插值)。

离散余弦变换的基函数及其相应系数(特定于我们的图像)。
显示两个DCT基图像的线性组合及结果模式的动画。
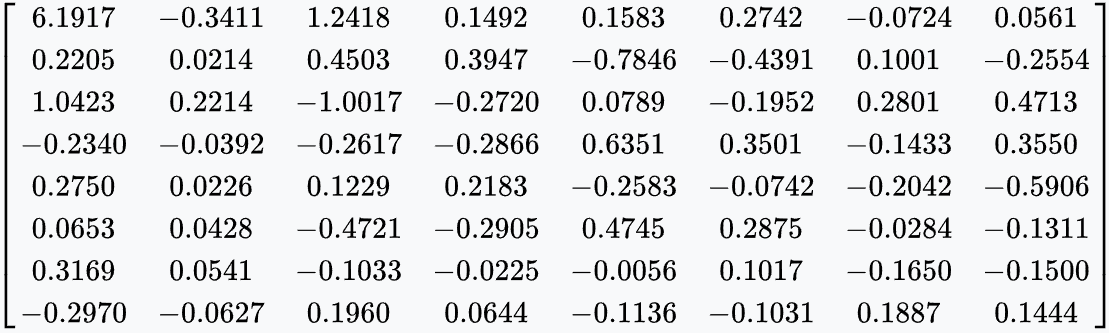
一个8×8块的DCT系数。能量集中在低频(左上角)。
量化¶

为了去除高频分量,DCT系数被量化表中的相应值相除。量化表中左上角值较小,右下角值较大的设计可以保留低频分量并抑制高频分量。对DCT系数进行量化,目的是减小非零系数的幅度并增加零系数的数量。量化可以使用如图所示的量化器来完成。
DC系数¶

4.低频分量位于左上角,F(0,0)是直流(DC)系数,表示8×8子块的平均值。由于两个相邻图像块的DC系数之差非常小,因此使用DPCM编码。其他63个元素是交流(AC)系数,它们以之字形顺序进行行程长度编码,以使零系数的值更集中。

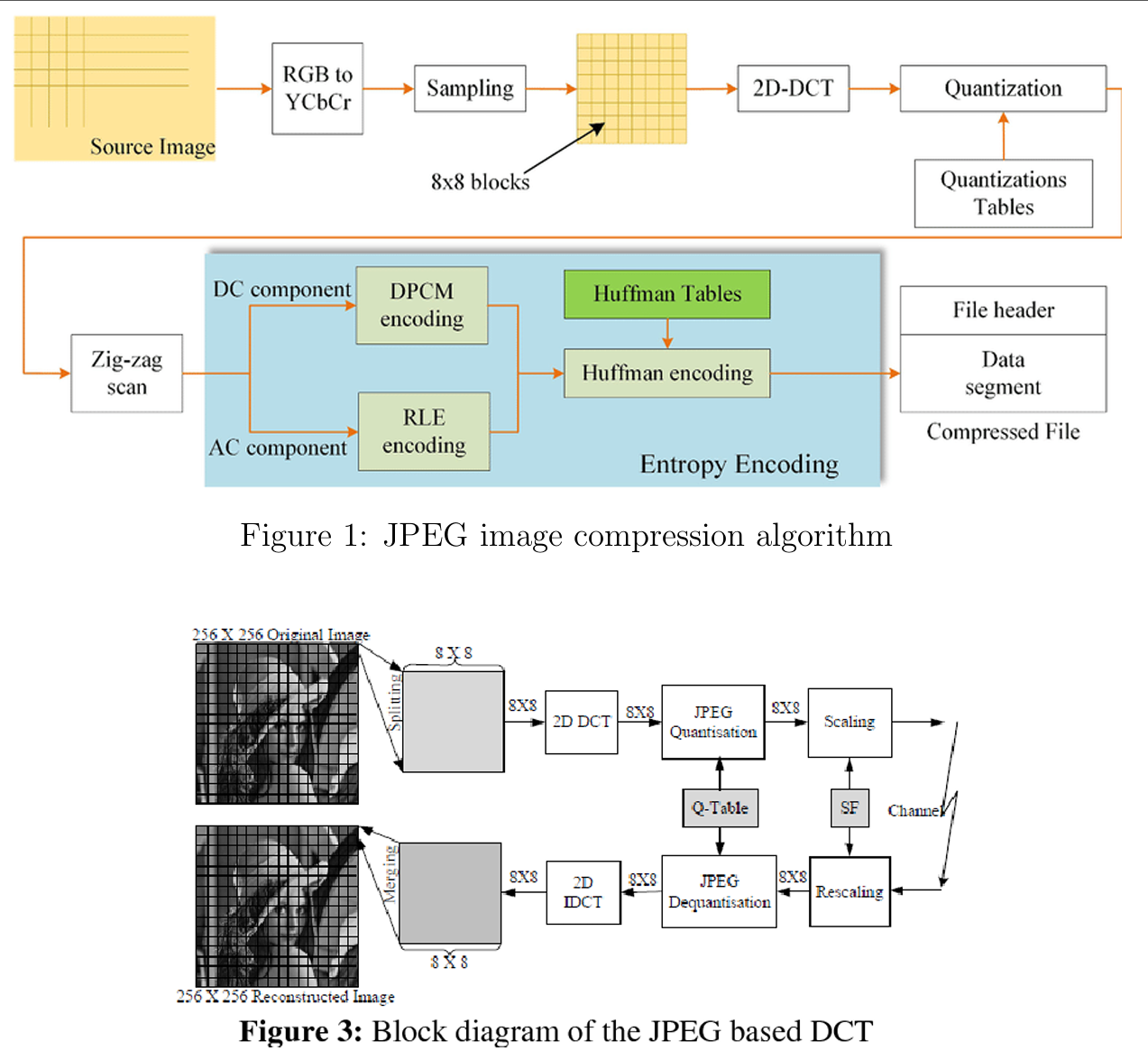

完整示例¶

总结¶
熵编码 霍夫曼编码、算术编码、行程长度编码、LZW编码
预测编码 DM编码、DPCM编码
块变换编码 KL变换编码、离散余弦变换
JPEG编码