邻域和连通性
在常规图像中,坐标为 的像素有四个水平和垂直邻域,其坐标由下式给出:
考虑这4个邻域,我们称之为4连通。
此外,还有四个对角像素,坐标为:
这些像素与4邻域共同构成了8连通中的8个邻域。

绿色像素的邻域以红色表示,分别为4连通(左)和8连通(右)。
坐标为 和 的两个像素之间的路径是一个像素序列,其中任意两个连续像素在所考虑的连通性中是邻域。
设 表示图像中的一个像素集合。如果两个像素之间存在一条完全由 中的像素组成的路径,则称这两个像素在 中是连通的。连通性是一种等价关系,因为它是自反的、对称的和传递的。
中所有相互连通的像素集合构成了 的一个连通分量。在图像中找到所有连通分量的过程是计算机视觉中的一个基本操作,称为连通分量标记。
4连通和8连通之间的选择很重要,可能导致不同的结果,如下图所示。这也可能导致拓扑悖论。例如,如果我们对象体使用4连通,那么对背景就应该使用8连通(反之亦然),以确保拓扑结构的一致性,即路径不会在没有交集的情况下交叉。

此图像中,使用4连通有两个连通分量,而使用8连通只有一个连通分量。
import numpy as np
import matplotlib.pyplot as plt
from skimage.measure import label
# 创建一个示例二值图像
image = np.array([
[0, 1, 1, 0, 0, 0],
[0, 1, 0, 1, 0, 0],
[0, 0, 0, 1, 1, 0],
[0, 0, 1, 0, 0, 0],
[1, 1, 0, 0, 1, 1],
[1, 0, 0, 1, 1, 0]
])
# 使用4连通标记连通分量
# connectivity参数指定将像素视为邻域的最大正交跳数。
# 1表示4连通(北、南、东、西),2表示8连通(包括对角线)。
labeled_4_conn = label(image, connectivity=1)
# 使用8连通标记连通分量
labeled_8_conn = label(image, connectivity=2)
# 显示结果
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
ax = axes.ravel()
ax[0].imshow(image, cmap='gray')
ax[0].set_title('原始二值图像')
ax[0].axis('off')
ax[1].imshow(labeled_4_conn, cmap='nipy_spectral')
ax[1].set_title(f'4-连通\\n({np.max(labeled_4_conn)} 个分量)')
ax[1].axis('off')
ax[2].imshow(labeled_8_conn, cmap='nipy_spectral')
ax[2].set_title(f'8-连通\\n({np.max(labeled_8_conn)} 个分量)')
ax[2].axis('off')
plt.tight_layout()
plt.show()
##种子填充算法
种子填充算法(也称为洪水填充)是识别图像中连通分量的基本方法。它从区域内的一个像素(即“种子”)开始,逐渐扩展以用新标签填充整个连通区域。此过程对于分割对象和分析二值图像中的空间关系特别有用。

DFS种子填充算法示意图。
算法步骤¶
种子填充算法的核心逻辑可概括如下:
遍历图像以找到一个未标记的前景像素 。此像素成为新连通分量的种子。
为位于 的种子像素分配一个新标签 。
根据所选的连通性(4连通或8连通)检查种子像素的邻域。
对于每个同样属于前景且尚未标记的相邻像素,重复步骤2。
此扩展过程将持续到连通分量中的所有像素都被分配了标签 。然后,对图像中任何剩余的未标记前景像素重复此过程,直到遍历整个图像。
深度优先实现¶
实现种子填充算法的常用方法是使用深度优先搜索(DFS)遍历。这可以通过递归或使用堆栈的迭代方法来实现。
以下是递归深度优先种子填充的伪代码:
seed_fill_recursive(image, x, y, label)
1. Set image(x, y) = label
2. For each neighbor (u, v) of (x, y):
3. If image(u, v) is an unlabeled foreground pixel:
4. seed_fill_recursive(image, u, v, label)另外,也可以使用堆栈实现迭代版本,以避免深度递归,这样更高效,并能防止在处理大型连通分量时发生堆栈溢出错误。
seed_fill_iterative(image, x, y, label)
1. Initialize an empty stack.
2. Push the seed coordinates (x, y) onto the stack.
3. While the stack is not empty:
4. Pop coordinates (u, v) from the stack.
5. If image(u, v) is an unlabeled foreground pixel:
6. Set image(u, v) = label
7. For each neighbor (s, t) of (u, v):
8. Push (s, t) onto the stack.以下动画演示了深度优先种子填充算法在4连通和8连通分量上的遍历模式。
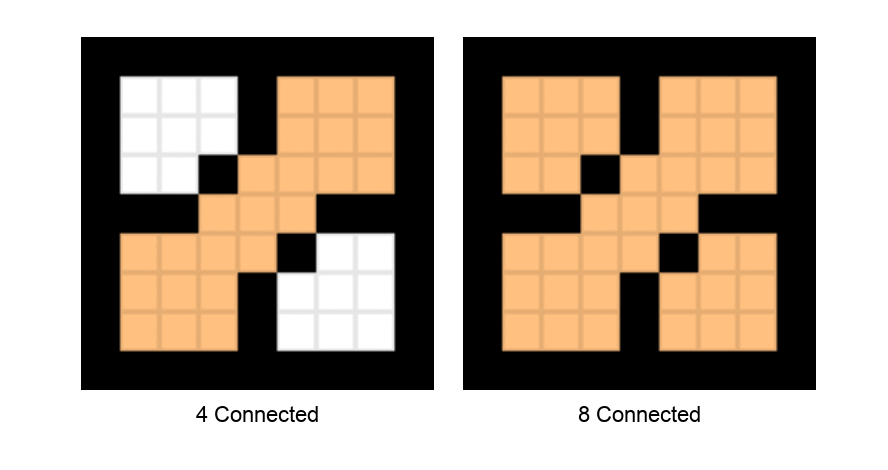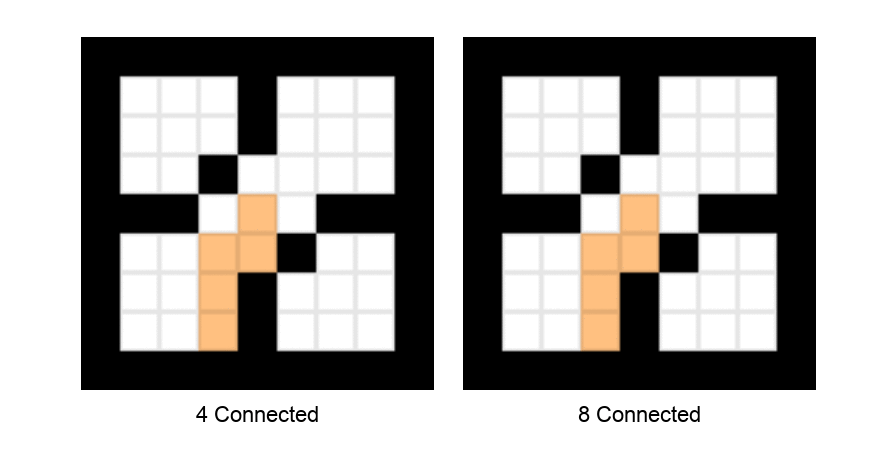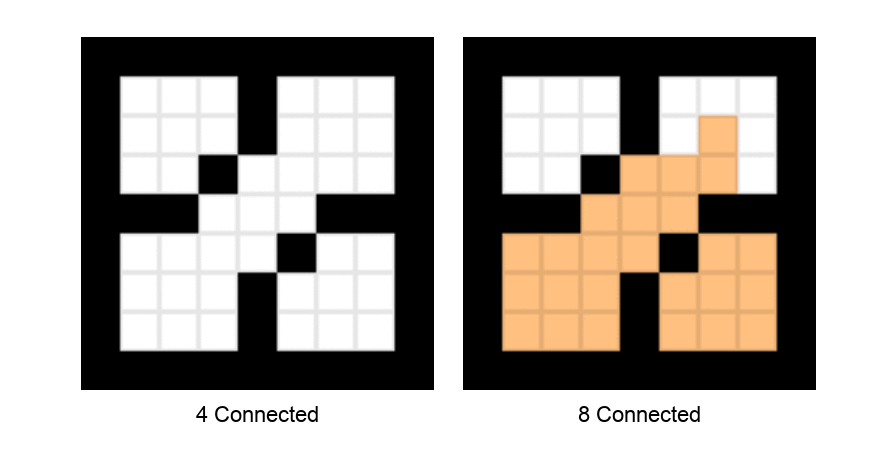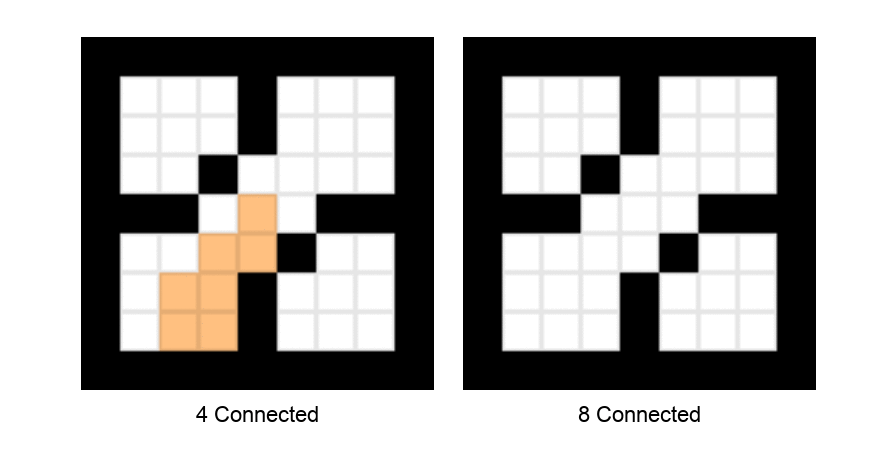
种子填充算法的深度优先遍历。 左侧显示4连通,右侧显示8连通。
虽然种子填充算法为寻找连通分量提供了概念基础,但在实践中,通常使用高度优化的库函数,如上文演示的 skimage.measure.label。这些实现通常更快、更稳健,能处理各种边缘情况,并通过优化的算法(如带并查集数据结构的两遍标记法)提供更好的性能。